📊 Experiments & Results
Evaluation Setup
Pre-training sparsification (finding masks for frozen random weights)
Benchmarks:
- MNIST (Image Classification)
- CIFAR-10 (Image Classification)
Metrics:
- Top-1 Accuracy
- Sparsity (percentage of pruned weights)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| MNIST (LeNet-300-100) | Top-1 Accuracy | 85 | 96 | +11 |
| CIFAR-10 (ResNet50) | Sparsity (%) | 50 | 91.5 | +41.5 |
| CIFAR-10 (ResNet50) | Top-1 Accuracy | 83.0 | 83.1 | +0.1 |
| Results on Transformer architectures (ViT and Swin-T) demonstrate the first successful identification of Strong Lottery Tickets in attention-based models. | ||||
| CIFAR-10 (ViT-base) | Top-1 Accuracy | Not reported in the paper | 76 | Not reported in the paper |
| CIFAR-10 (Swin-T) | Top-1 Accuracy | 87.26 | 80 | -7.26 |
Experiment Figures
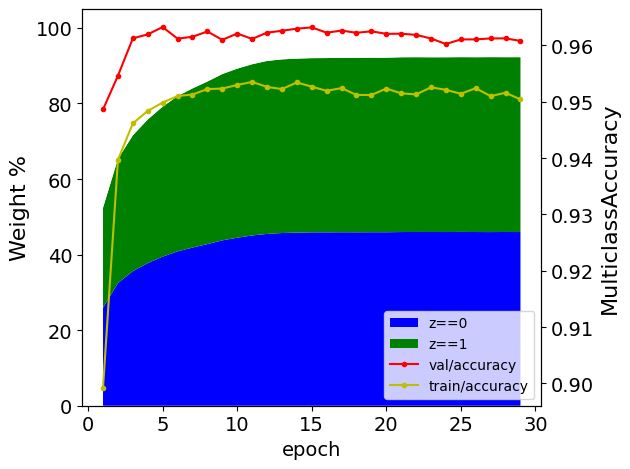
Accuracy vs. Sparsity trade-off for LeNet-300-100 on MNIST
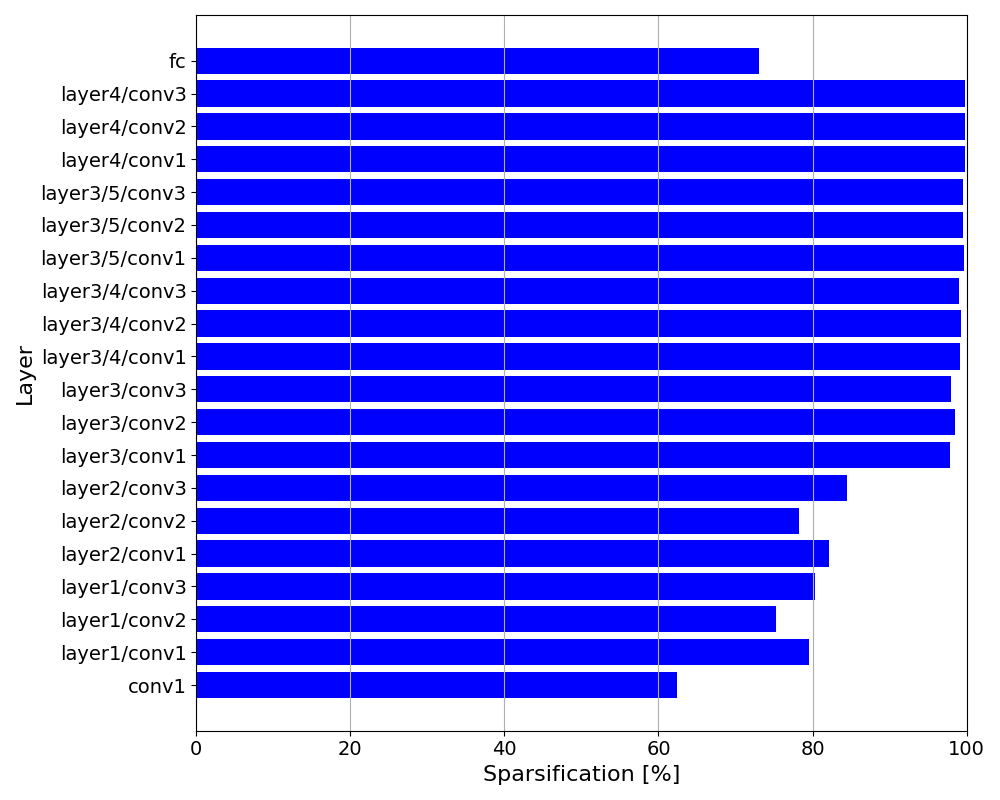
Per-layer sparsity rates for ResNet50 on CIFAR-10
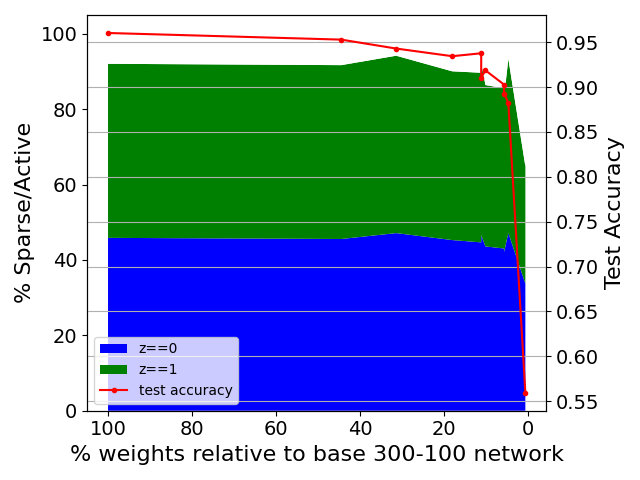
Robustness of SLT identification when base network size is reduced
Main Takeaways
- Differentiable relaxed gates allow finding much sparser strong lottery tickets (90%+) than prior score-based methods (50%) for similar accuracy.
- Method works consistently across FCNs, CNNs (ResNet, WideResNet), and Transformers (ViT, Swin), showing architectural generalization.
- For ResNet50, layers are sparsified non-uniformly: later layers are pruned much more heavily than early layers, preserving low-level feature extraction.
- Wider networks (Wide-ResNet50) provide a richer search space, yielding higher accuracy (88%) than standard ResNet50 (83.1%) at similar high sparsity (~90%).