📝 Paper Summary
Human-in-the-loop Optimization
Robot Preference Learning
CMA-ES-IG improves robot preference learning by filtering evolutionary search samples with clustering, creating queries that are both perceptually distinct for users and informative for optimization.
Core Problem
Existing preference learning methods either generate indistinguishable queries that are hard to rank (implicit methods) or disjoint queries that feel random and unintuitive to users (explicit methods).
Why it matters:
- Users frequently provide noisy or inconsistent feedback when robot behaviors look too similar, degrading learning efficiency
- Purely information-theoretic queries often fail to demonstrate behavioral improvement, causing users to perceive a lack of progress and lose trust in the system
- Robots in human-centered environments need to adapt to non-expert preferences without requiring programming knowledge or perfect feedback
Concrete Example:
When a user wants a robot to move 'cautiously,' a standard optimizer might present two trajectories that both look slightly fast and nearly identical. The user struggles to rank them reliably, providing noisy data. CMA-ES-IG forces the robot to show distinct variations (e.g., one clearly slower than the other) while still refining the overall motion.
Key Novelty
Covariance Matrix Adaptation Evolution Strategy with Information Gain (CMA-ES-IG)
- Integrates the exploration power of evolutionary strategies (CMA-ES) with the distinguishability of Information Gain (IG)
- Replaces random sampling with a 'quantization' step: partitions the search distribution using K-means clustering and uses centroids as queries
- Ensures candidate behaviors are sufficiently diverse for users to rank easily, reducing noise while maintaining the optimization trajectory
Architecture
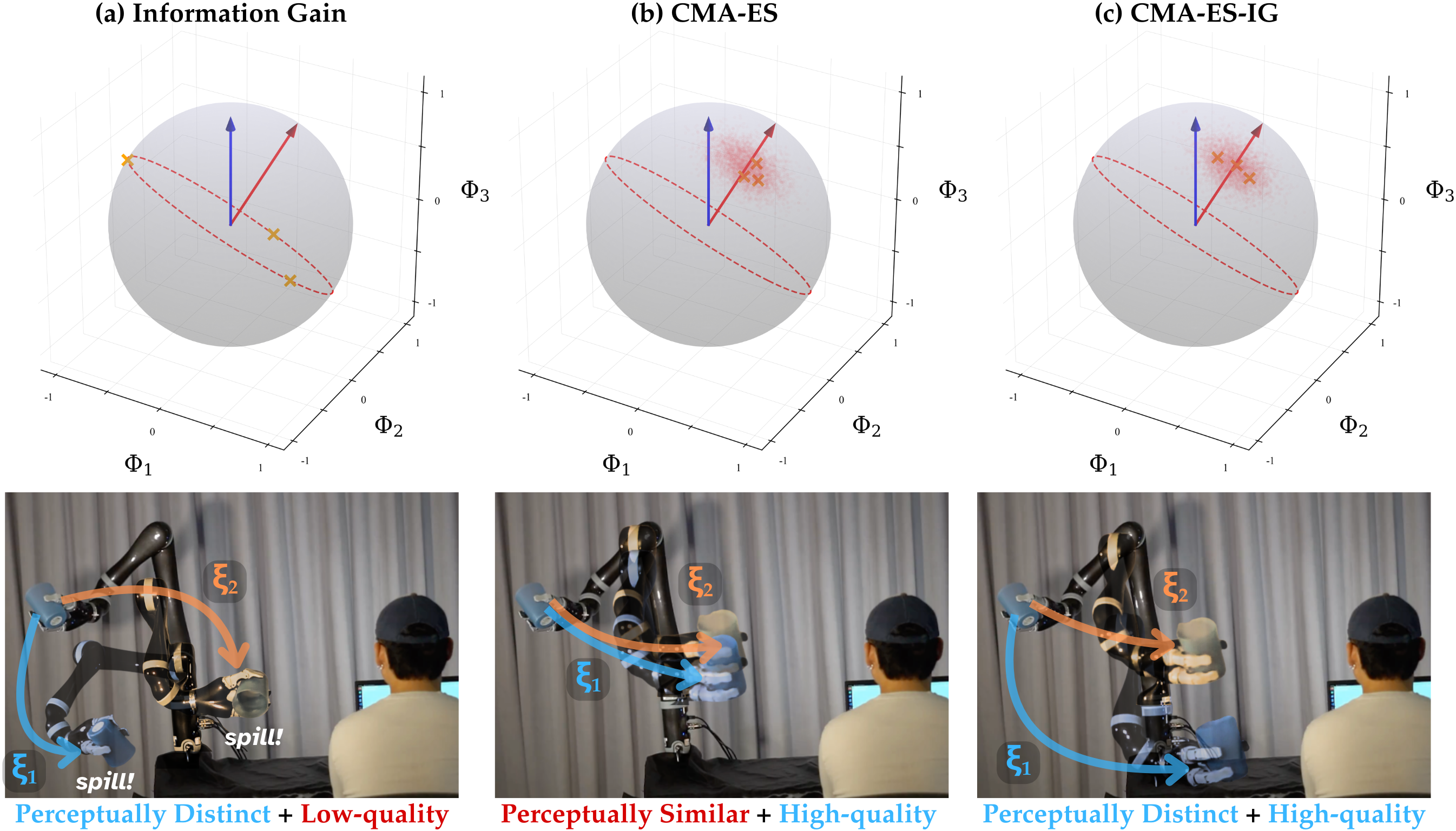
The iterative loop of generating candidates, clustering them to find diverse queries, obtaining user rankings, and updating the search distribution.
Breakthrough Assessment
7/10
Addresses a critical usability gap in human-in-the-loop learning by prioritizing the user's perception of the teaching process, not just final accuracy. The combination of clustering with CMA-ES is an intuitive practical fix.