📝 Paper Summary
Medical Multi-modal Large Language Models
Agentic AI
Model Distillation
Meissa distills complex medical agent behaviors (tool use, multi-step reasoning) from large proprietary models into a lightweight 4B-parameter model executable offline by training on stratified, error-driven trajectories.
Core Problem
Current high-performance medical agents rely on proprietary frontier models (e.g., GPT-4) via cloud APIs, making them unsuitable for clinical settings due to high cost, latency, and privacy risks.
Why it matters:
- Patient data privacy regulations often prohibit sending medical images to external cloud APIs.
- Repeated API calls for multi-step agentic reasoning create prohibitive costs and latency that disrupt real-time clinical workflows.
- Existing small models lack the 'agentic' ability to decide when to use tools versus answering directly, limiting them to single-pass tasks.
Concrete Example:
A clinician needs a diagnosis from a CT scan. A frontier agent might invoke a segmentation tool, analyze the mask, and debate with a sub-agent, taking 30+ seconds and costing $0.50 via API. A standard small model just guesses immediately and incorrectly. Meissa runs this multi-step process locally in ~1.4s.
Key Novelty
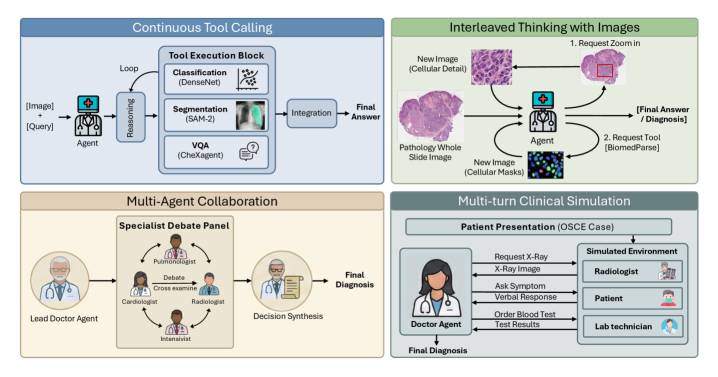
Unified Agentic Behavior Distillation via Stratified Supervision
- Treats 'strategy selection' (whether to use tools) as a learned behavior by training on a mix of direct answers (for easy queries) and tool-use trajectories (for hard queries) based on model error rates.
- Unifies heterogeneous agent environments (tool calling, visual reasoning, multi-agent debate) into a single state-action-observation format, allowing one model to master all interaction modes.
- Uses 'prospective-retrospective' training: pairs exploratory forward traces (what happened) with clean hindsight summaries (why it happened) to stabilize policy learning.
Architecture
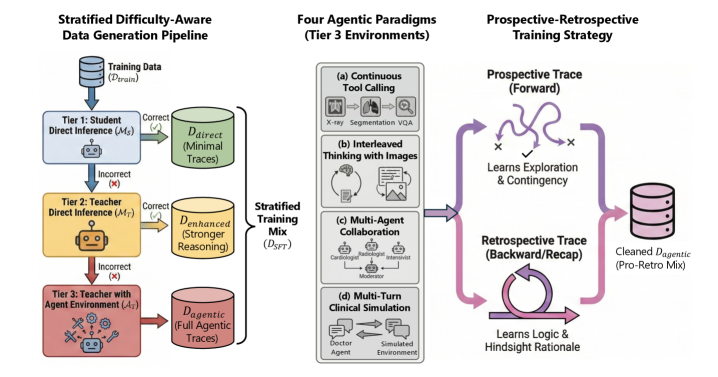
Overview of the Meissa framework, illustrating the stratified data synthesis pipeline and the unified trajectory learning.
Evaluation Highlights
- Matches or exceeds proprietary frontier agents (Gemini-Pro-1.5, GPT-4o) in 10 of 16 evaluation settings across 13 medical benchmarks.
- Reduces end-to-end latency by ~22x compared to API-based frontier agent deployment.
- Uses >25x fewer parameters (4B) than typical frontier models like Gemini-3 while maintaining competitive performance.
Breakthrough Assessment
9/10
Successfully distills complex agentic reasoning—usually reserved for massive models—into a deployable 4B model. The stratified supervision strategy elegantly solves the 'when to act' routing problem without a separate router.