📝 Paper Summary
Robotic World Models
Video Generation for Robotics
Sim-to-Real Transfer
PlayWorld trains high-fidelity robotic video world models using large-scale, unsupervised interaction data collected by a robot playing autonomously under VLM guidance.
Core Problem
Current robotic video models are trained on human demonstrations, which are biased toward success and lack the diverse, contact-rich failure cases needed to learn robust physics.
Why it matters:
- Models trained only on successes hallucinate unrealistic physics (e.g., objects disappearing or merging) when a policy deviates even slightly from the expert path.
- Reliable world models are essential for policy evaluation and reinforcement learning in simulation to avoid expensive and dangerous real-world trials.
- Human data collection is unscalable and labor-intensive, limiting the diversity of interactions a model can learn from.
Concrete Example:
When a robot attempts to push an object but grazes it (a counterfactual action not in human demos), standard video models often hallucinate the object sliding perfectly or disappearing, rather than tipping over or rotating as physics dictates.
Key Novelty
Autonomous Play for World Model Learning
- Uses a Vision-Language Model (VLM) to propose diverse tasks and a Vision-Language-Action (VLA) model to execute them, allowing the robot to explore object interactions without human supervision.
- Introduces a 'distance-to-success' curriculum that prioritizes learning from rare, contact-rich interactions found in play data over repetitive successful motions.
Architecture
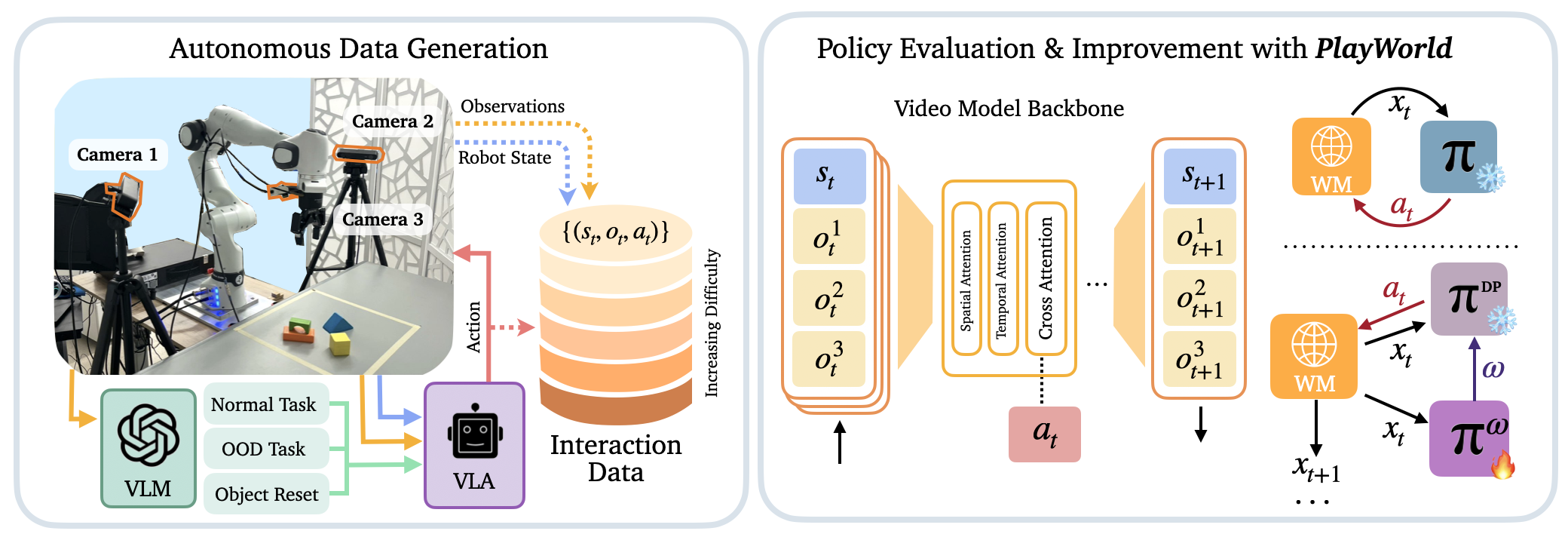
The PlayWorld Data Collection System (The 'Inference' workflow of the data gathering engine)
Evaluation Highlights
- Improves real-world policy success rates by 65% when used for Reinforcement Learning (RL) fine-tuning compared to pre-trained policies.
- Achieves up to 40% improvement in failure prediction accuracy over world models trained on human-collected demonstration data.
- Visual fidelity metrics continue to improve at 5x the data scale where performance saturates for models trained on human demonstrations.
Breakthrough Assessment
8/10
Significant step in autonomous data generation for robotics. Demonstrates that unstructured play data is superior to expert demos for world modeling, with strong real-world transfer results.