📝 Paper Summary
Context Modeling
Transformer Architecture
Exclusive Self Attention (XSA) improves sequence modeling by projecting attention outputs to be orthogonal to the current token's value vector, effectively removing redundant self-information and forcing focus on the context.
Core Problem
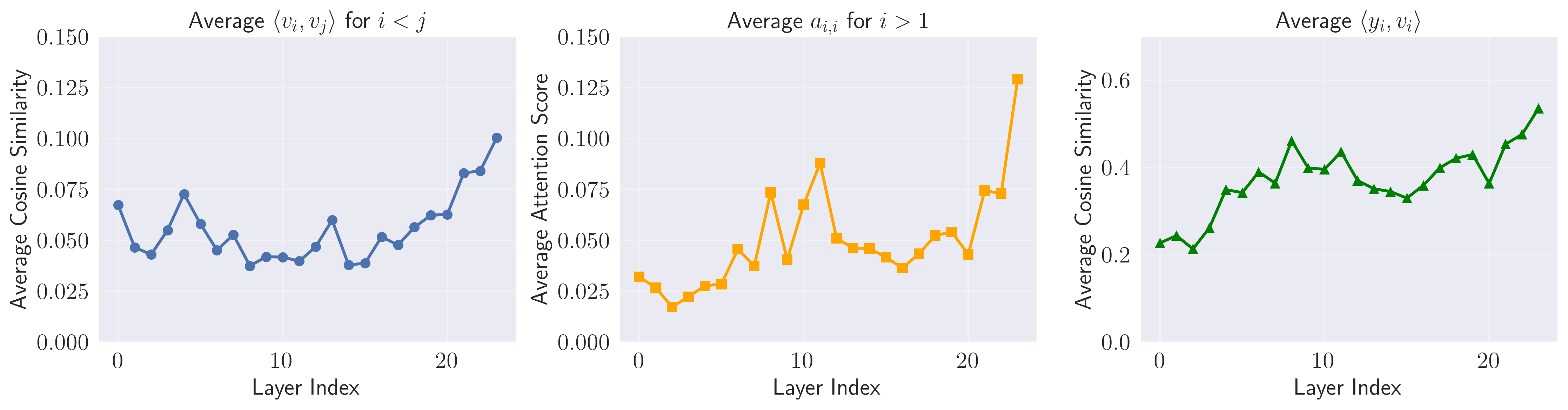
Standard Self Attention (SA) suffers from 'attention similarity bias,' where the output is highly correlated with the current token's own value vector.
Why it matters:
- This redundancy is inefficient because the Feed Forward Network (FFN) already handles point-wise feature updates via residual connections
- It creates competition between modeling the current token versus the surrounding context, diminishing the attention mechanism's ability to aggregate contextual information
- Long-context modeling suffers when attention capacity is wasted on self-redundant information
Concrete Example:
In a standard Transformer, if the current token is 'apple', the attention head often outputs a vector very similar to 'apple' itself. XSA subtracts this 'apple' component from the output, forcing the attention head to instead pass forward contextual signals (like 'red' or 'fruit') that are orthogonal to 'apple'.
Key Novelty
Orthogonal Output Projection (Exclusive Self Attention)
- Modifies the standard attention output by subtracting its projection onto the current token's value vector
- Mathematically ensures the attention output contains zero component of the self-value, eliminating the 'attention similarity bias' entirely
- Acts as an implicit 'attention sink' by allowing the model to dump unnecessary attention weight onto the self-position without polluting the propagated signal
Architecture
Conceptual flow of the XSA modification
Evaluation Highlights
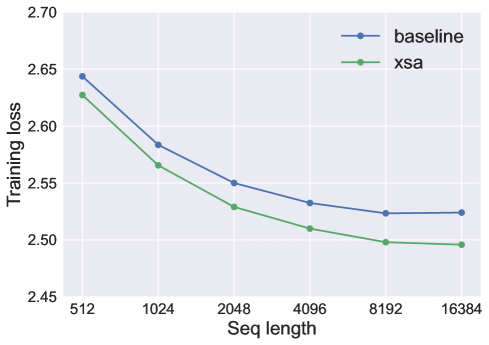
- Consistently achieves better training and validation loss than standard Self Attention across 0.7B, 1.4B, and 2.7B parameter models (exact loss values not reported in text)
- Demonstrates larger performance gains relative to baseline as sequence length increases (tested up to 16,384 tokens)
- Maintains minimal computational overhead in terms of speed and memory compared to standard attention
Breakthrough Assessment
7/10
A simple, theoretically grounded modification (orthogonal projection) that addresses a specific architectural redundancy (similarity bias) with consistent empirical gains, though the text lacks specific numeric deltas to verify the magnitude of improvement.