📝 Paper Summary
LLM Pretraining Optimization
Matrix-based Optimizers
Heavy-Tailed Self-Regularization
HTMuon improves the Muon optimizer by raising singular values of the momentum matrix to a power p < 1, inducing heavy-tailed weight spectra associated with better generalization.
Core Problem
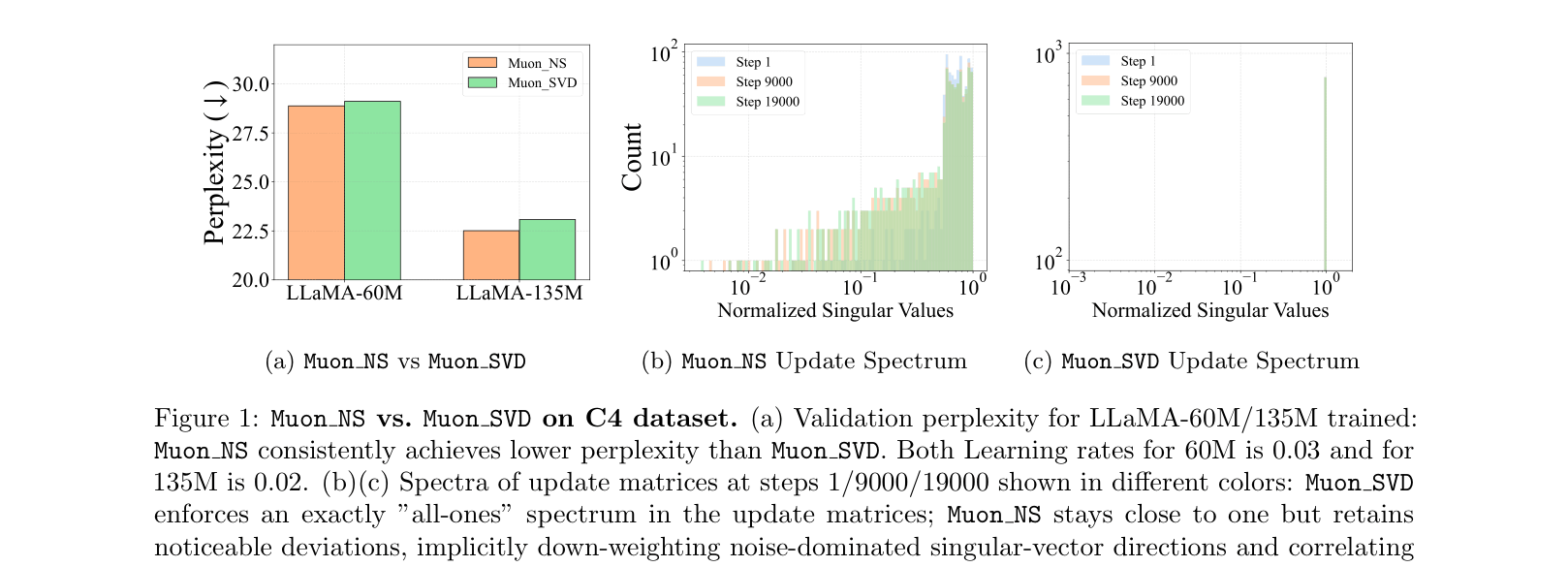
The Muon optimizer's orthogonalization step sets all singular values to one, which suppresses heavy-tailed weight spectra (correlated with better generalization) and over-emphasizes noise-dominated directions.
Why it matters:
- Muon's performance often degrades with model scale and training duration compared to vector-based optimizers like Adam
- HT-SR (Heavy-Tailed Self-Regularization) theory suggests well-trained networks naturally exhibit heavy-tailed weight spectra; suppressing this limits model quality
- Uniformly weighting all singular vector directions includes noise-dominated small singular values, potentially hurting convergence stability
Concrete Example:
In Muon, if a singular value in the momentum matrix is very small (representing noise), the orthogonalization step boosts it to 1.0, amplifying noise. HTMuon keeps it smaller (by raising to power p), effectively filtering noise while maintaining heavy tails.
Key Novelty
Heavy-Tailed Spectral Correction for Matrix Optimizers
- Modifies Muon's update rule by raising momentum singular values to a power p (0 < p < 1) instead of setting them all to 1 (orthogonalization)
- Acts as a bridge between Muon (p=0) and SGDM (p=1), preserving matrix-based parameter coupling while allowing heavy-tailed updates
- Theoretically corresponds to steepest descent under a Schatten-q norm constraint rather than Muon's Schatten-infinity norm
Architecture
The core logic of the HTMuon optimizer.
Evaluation Highlights
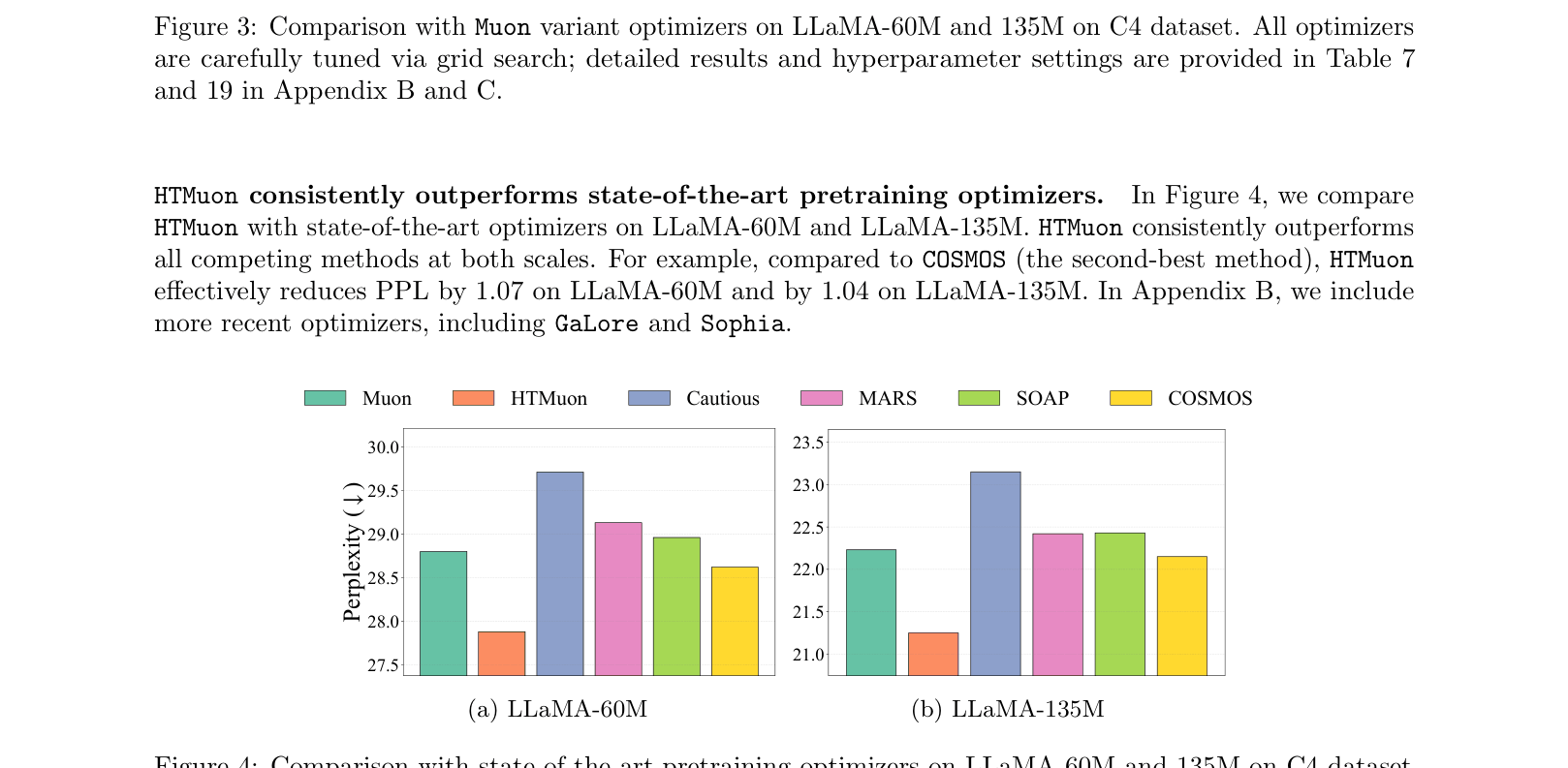
- Reduces perplexity by 0.98 compared to Muon when pretraining LLaMA-135M on C4 dataset
- Outperforms state-of-the-art optimizers (AdamW, SOAP, MARS, COSMOS) across LLaMA sizes (60M, 135M, 350M, 1B)
- Improves accuracy on ImageNet-1K with ViT-Tiny (+0.14% vs Muon) and CIFAR-100 with ResNet50 (+0.31% vs Muon)
Breakthrough Assessment
8/10
Strong empirical results consistently outperforming Muon and AdamW across scales. Theoretical grounding in HT-SR and Schatten-norms provides a solid justification for the modification.