📝 Paper Summary
Medical Vision-Language Pretraining
Vision Transformer (ViT) distillation
VIVID-Med pretrains a medical Vision Transformer by distilling structured, verifiable knowledge from a frozen LLM using JSON-based supervision and orthogonal query decomposition, discarding the heavy LLM before deployment.
Core Problem
Current medical vision-language models supervise visual encoders with one-hot labels or free-form text, which fail to capture complex relationships among clinical findings and result in resource-heavy models unsuitable for clinical deployment.
Why it matters:
- One-hot vectors treat co-occurring conditions (e.g., pleural effusion and pulmonary edema) as strictly orthogonal, missing pathophysiological links.
- Free-text descriptions vary wildly in phrasing, masking underlying clinical relatedness.
- Existing instruction-driven methods (like ViTP) require keeping the massive LLM active during inference, creating high computational costs for clinical settings.
Concrete Example:
A one-hot label vector treats 'pleural effusion' and 'pulmonary edema' as unrelated, while free text might describe them vaguely. VIVID-Med forces the model to predict a structured JSON state for each, capturing their correlation via the LLM's embedding space.
Key Novelty
Verifiable Instruction-driven Visual Intelligence Deployment (VIVID-Med)
- Uses a frozen LLM as a 'structured semantic teacher' to supervise a ViT, but discards the LLM after training to yield a lightweight vision-only backbone.
- Unified Medical Schema (UMS) converts clinical findings into a verifiable JSON format with answerability masking to filter noisy gradients from unassessable findings.
- Structured Prediction Decomposition (SPD) breaks visual attention into orthogonal groups, forcing the model to learn diverse, complementary anatomical features rather than collapsing on dominant signals.
Architecture
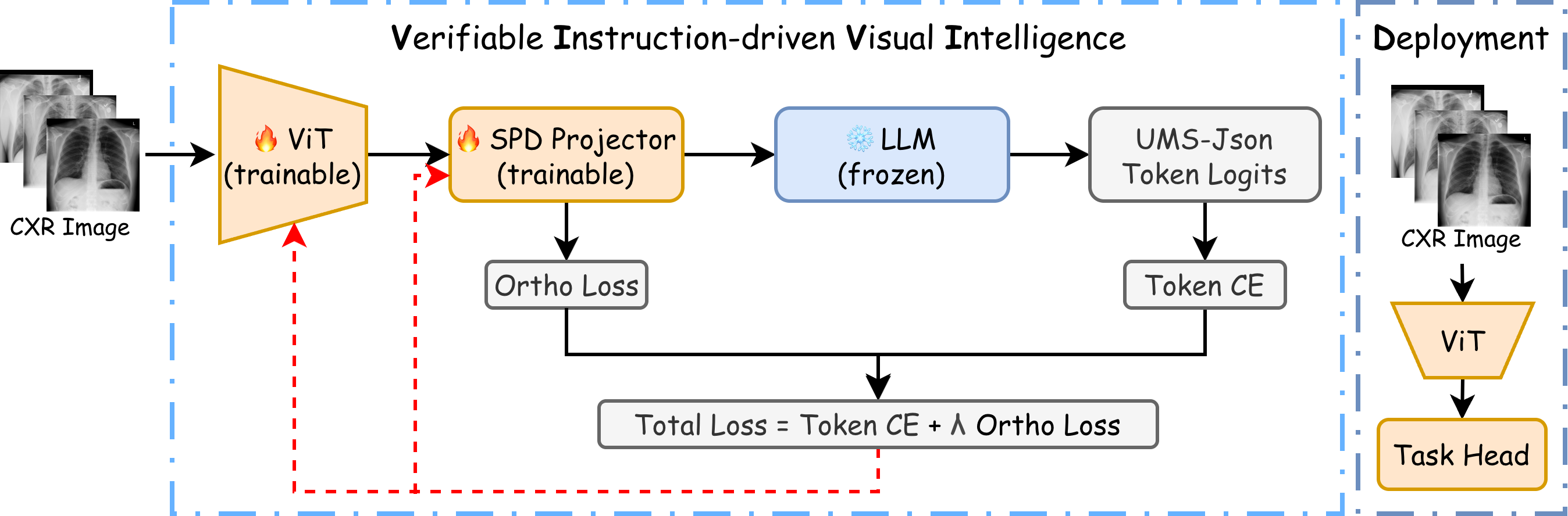
The VIVID-Med training pipeline, showing the interaction between the ViT, SPD projector, and frozen LLM.
Evaluation Highlights
- Achieves 0.8588 macro-AUC on CheXpert linear probing, outperforming BiomedCLIP by +6.65 points despite using 500x less data.
- Demonstrates robust zero-shot transfer to NIH ChestX-ray14 with 0.7225 macro-AUC (+5.00 points over BiomedCLIP).
- Achieves near-perfect 0.9969 macro-AUC on OrganAMNIST (CT) without ever seeing CT data during pretraining, showing strong cross-modality generalization.
Breakthrough Assessment
8/10
Strong conceptual novelty in decoupling semantic supervision (LLM) from deployment (ViT-only). Significant efficiency gains (500x less data) and cross-modality performance make it highly practical for medical AI.