📝 Paper Summary
Class-Incremental Learning (CIL)
Expansion-based Continual Learning
Causal Representation Learning
The paper proposes a causal regularization framework for expansion-based class-incremental learning that mitigates feature collision by enforcing intra-task causal completeness and inter-task separability via twin-network counterfactual generation.
Core Problem
Expansion-based CIL methods suffer from feature collision, where new task-specific features (learned via ERM) rely on 'shortcuts' that accidentally overlap with the frozen features of previous tasks.
Why it matters:
- Standard ERM (Empirical Risk Minimization) prioritizes minimal discriminative cues (shortcuts), leading to non-robust features that lack full semantic meaning
- When new classes share semantic attributes with old classes (e.g., similar ear shapes), these shortcut features drift into the old feature space, causing misclassification
- Existing methods focus on feature diversity but fail to ensure the causal completeness required to distinguish new concepts from frozen old representations
Concrete Example:
Consider learning 'Wolf vs. Cat' (Task 1) then 'Dog vs. Lynx' (Task 2). The model might distinguish wolves by 'ear shape'. When dogs arrive (sharing ear shapes), the frozen wolf model captures the ear feature. To distinguish dogs without altering the frozen model, the new module learns a different shortcut (e.g., 'eye texture'). Result: Neither model captures the whole animal, and the shared 'ear' attribute causes the dog input to falsely trigger the frozen wolf representation.
Key Novelty
CPNS (Causal Probability of Necessity and Sufficiency) Regularization
- Extends the causal concept of Probability of Necessity and Sufficiency (PNS) to CIL, creating a unified metric (CPNS) that measures both intra-task feature completeness and inter-task separability
- Uses a 'Twin Network' generator to create counterfactual features: it perturbs inputs to simulate 'collision' states (forcing new features to look like old ones) and penalizes the model if it cannot distinguish them
Architecture
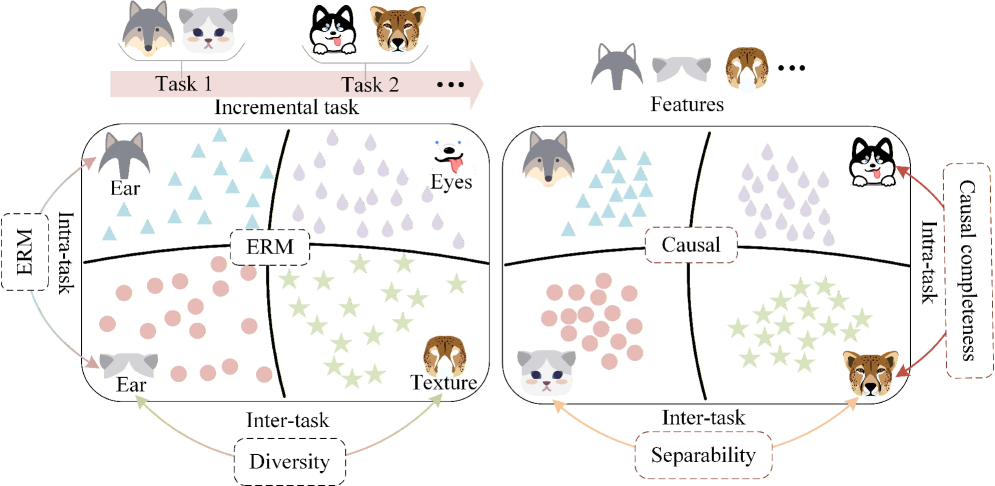
Structural Causal Models (SCM) illustrating the data generation process (Left) and the expansion-based learning process (Right). It highlights how ERM leads to reliance on minimal sufficiency factors (shortcuts) rather than complete causal factors.
Breakthrough Assessment
7/10
The application of formal causal necessity/sufficiency (PNS) to the specific problem of feature collision in CIL is theoretically novel and addresses a fundamental weakness of ERM-based expansion.