📊 Experiments & Results
Evaluation Setup
Code Obfuscation (Forward) and Deobfuscation (Reverse) tasks
Benchmarks:
- CodeNet (subset) (Code Transformation (Java))
- ConDefects (subset) (Evaluation Set (300 samples))
Metrics:
- CodeBLEU (Syntactic Similarity)
- Readability Score (0-1 scale)
- compilation rate
- execution success
- test case pass rate
- Statistical methodology: Spearman's correlation for relationship analysis; Chi-square tests for pattern distribution
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Standard Fine-Tuning (Forward Task) Performance: Models learn to obfuscate well, especially on simpler tasks, but struggle with algorithmic complexity. | ||||
| CodeNet (Obfuscation) | Success Rate (Variable Renaming) | 100.0 | 81.3 | -18.7 |
| CodeNet (Obfuscation) | Success Rate (String Encryption) | 100.0 | 29.7 | -70.3 |
| Reverse Task (Deobfuscation) Performance: Standard fine-tuning results in complete failure to deobfuscate, proving cognitive specialization. | ||||
| CodeNet (Reverse) | Success Rate (Reverse) | High | 0 | Not applicable |
| Contrastive Fine-Tuning (CFT) Results: CFT enables bidirectional capabilities. | ||||
| CodeNet (Reverse) | Success Rate (Deobfuscation) | 0 | 52 | +52 |
Experiment Figures
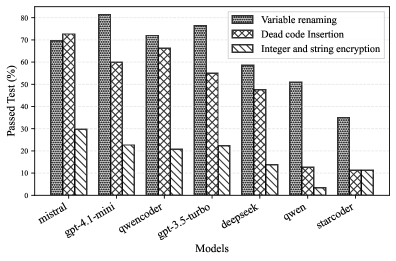
Performance hierarchy across transformation types (Renaming > Dead Code > Encryption) and failure analysis (Wrong Output vs Crash vs Compilation Error)
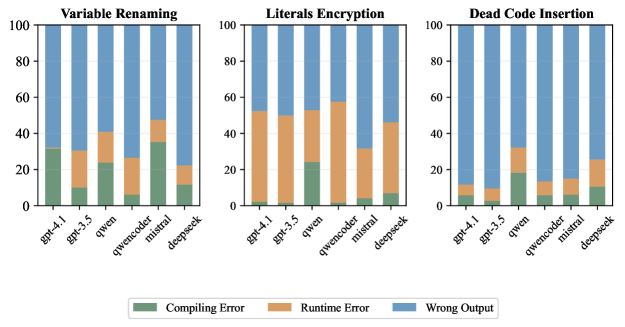
Deobfuscation failure analysis showing high syntactic similarity to the *obfuscated* input rather than the original target
Main Takeaways
- Cognitive Specialization is real: Fine-tuning on forward tasks (obfuscation) actively degrades the ability to reason in reverse, even for reversible logic.
- Models prioritize surface-level pattern matching over semantic understanding; this is evidenced by their ability to mimic syntax (CodeBLEU) while failing execution tests.
- Self-correction has limits: It helps fix syntax errors (compilation) but often leads to 'wrong outputs' (logic errors) rather than true fixes, plateauing after ~5 iterations.
- Contrastive Fine-Tuning successfully mitigates cognitive specialization, allowing models to learn the underlying principle of a transformation rather than just the forward mapping.