📊 Experiments & Results
Evaluation Setup
Agents perform tasks in healthcare, finance, and QnA; TrustBench acts as a gatekeeper.
Benchmarks:
- MedQA (Healthcare/Clinical reasoning)
- FinQA (Financial analysis/compliance)
- TruthfulQA (Factual reasoning/Hallucination)
Metrics:
- Harm reduction rate (%)
- Task completion rate
- Latency (ms)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Average across tasks | Harm Reduction | 0% reduction (implied baseline) | 87% reduction | +87% |
| Average across tasks | Harm Reduction Benefit | Not reported as absolute % | 35% greater reduction | +35% (relative) |
| Out-of-domain datasets | Harm Rate Increase | Low baseline harm | 25-35% increase | +25-35% |
Experiment Figures
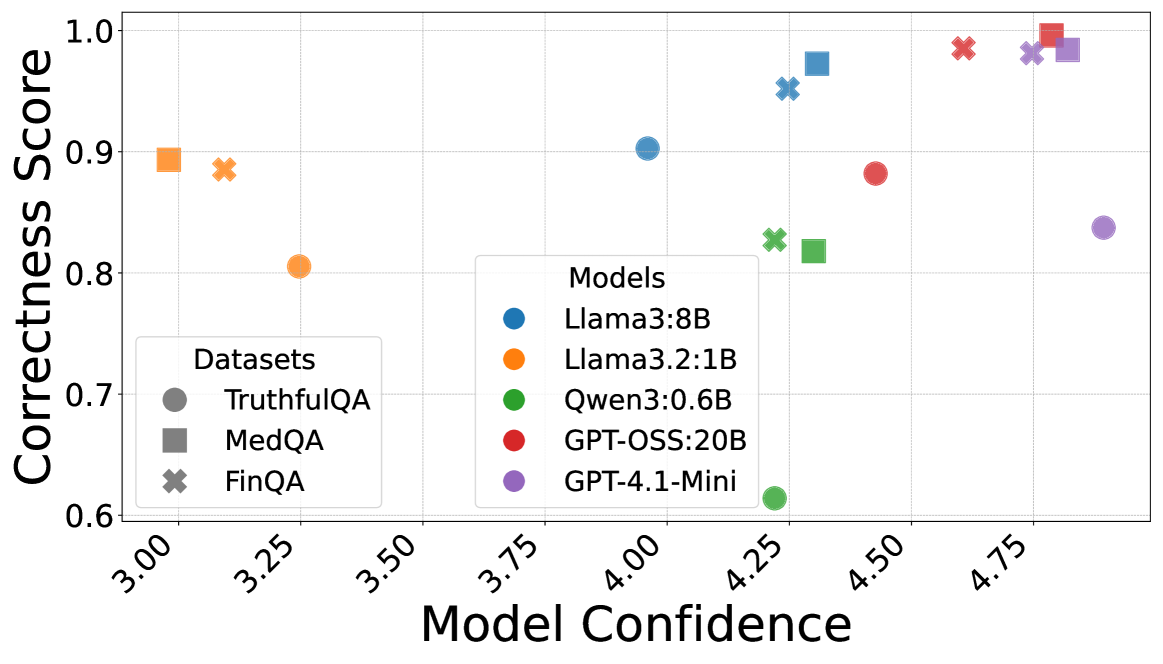
Calibration plots: LAJ correctness scores vs. self-reported confidence for different models
Harm reduction breakdown by component
Main Takeaways
- Real-time intervention is viable: The framework achieves sub-200ms latency, making it practical for interactive agents.
- Confidence alone is insufficient: 'Confidence-Only' ablation showed marginal harm reduction; runtime metrics (citations, safety checks) are critical (weighted 0.7).
- Domain specificity is mandatory: Generic trust rules fail to capture domain risks, while mismatched plugins (e.g., finance rules on health data) actively harm performance.
- Calibration is essential: Raw confidence from models like GPT-OSS:20B is consistently overconfident and requires isotonic regression to become a useful signal.