📝 Paper Summary
Dense Image Captioning
Reinforcement Learning with Verifiable Rewards (RLVR)
Vision-Language Model (VLM) Post-training
RubiCap enables reinforcement learning for open-ended dense captioning by using a committee of teacher VLMs to synthesize fine-grained, image-specific evaluation rubrics that serve as interpretable, verifiable reward signals.
Core Problem
Dense image captioning lacks deterministic verification methods (like math or code checkers), making Reinforcement Learning difficult to apply because quality is subjective and open-ended.
Why it matters:
- Supervised Fine-Tuning (SFT) often leads to model collapse, hallucination, and catastrophic forgetting of pre-trained capabilities
- Existing RL rewards using N-gram metrics (CIDEr) or scalar VLM-as-a-judge scores are too coarse, opaque, or easily gamed (reward hacking)
- Scaling expert-quality manual annotations for dense captioning is prohibitively expensive
Concrete Example:
In an image of a cake with text, a student model might describe the cake but miss the inscription. A standard VLM judge might give a generic high score for 'good description,' failing to penalize the omission. RubiCap's rubric writer identifies the text '24 CARROT CAKE' from teacher consensus and creates a specific binary check: 'Does the caption mention 24 CARROT CAKE?', forcing the student to learn this detail.
Key Novelty
Rubric-Guided Reinforcement Learning
- Replaces scalar rewards with a 'committee of teachers' that generates a sample-specific checklist (rubric) for each image
- Uses an LLM 'Rubric Writer' to diagnose specific deficiencies in the student model relative to teacher consensus (e.g., missing objects, wrong text)
- Converts subjective quality assessments into a set of binary, easy-to-check rules that an LLM judge can reliably verify
Architecture
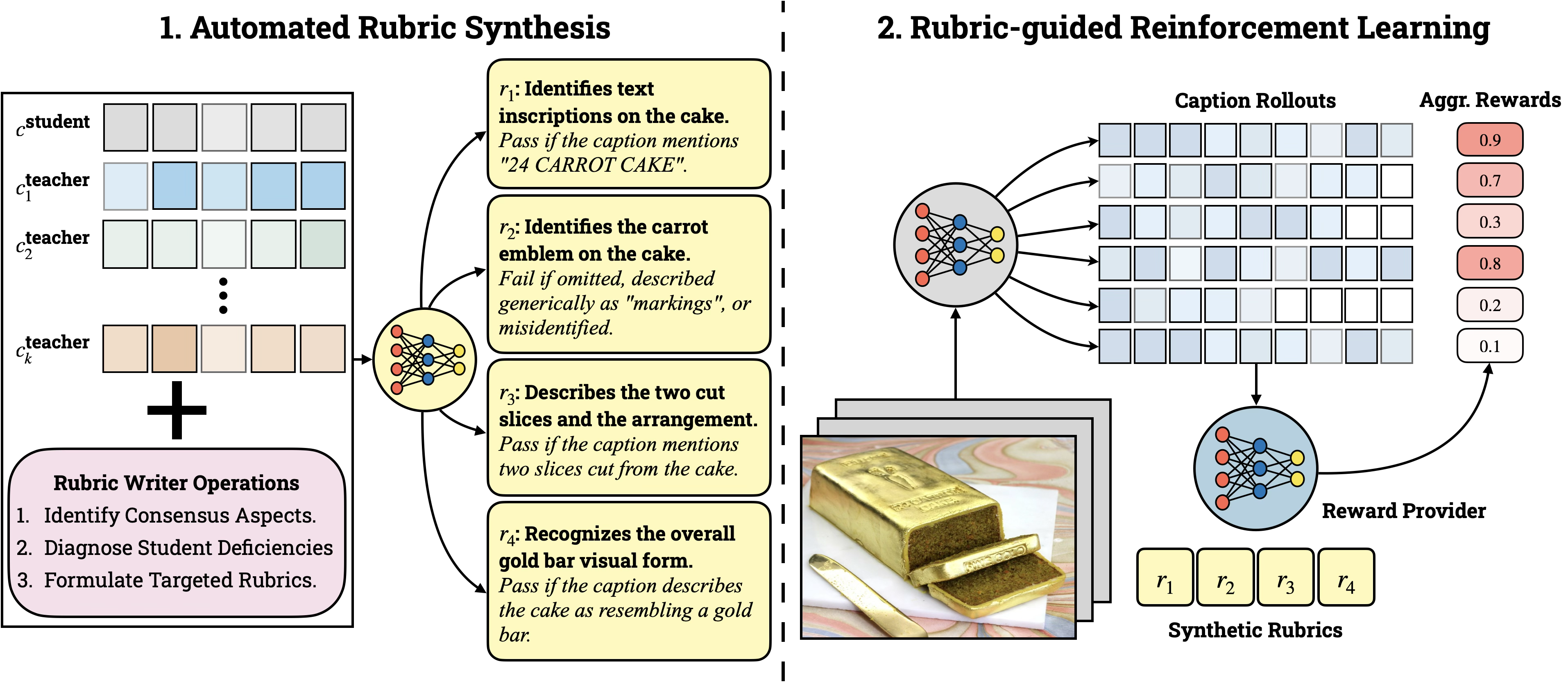
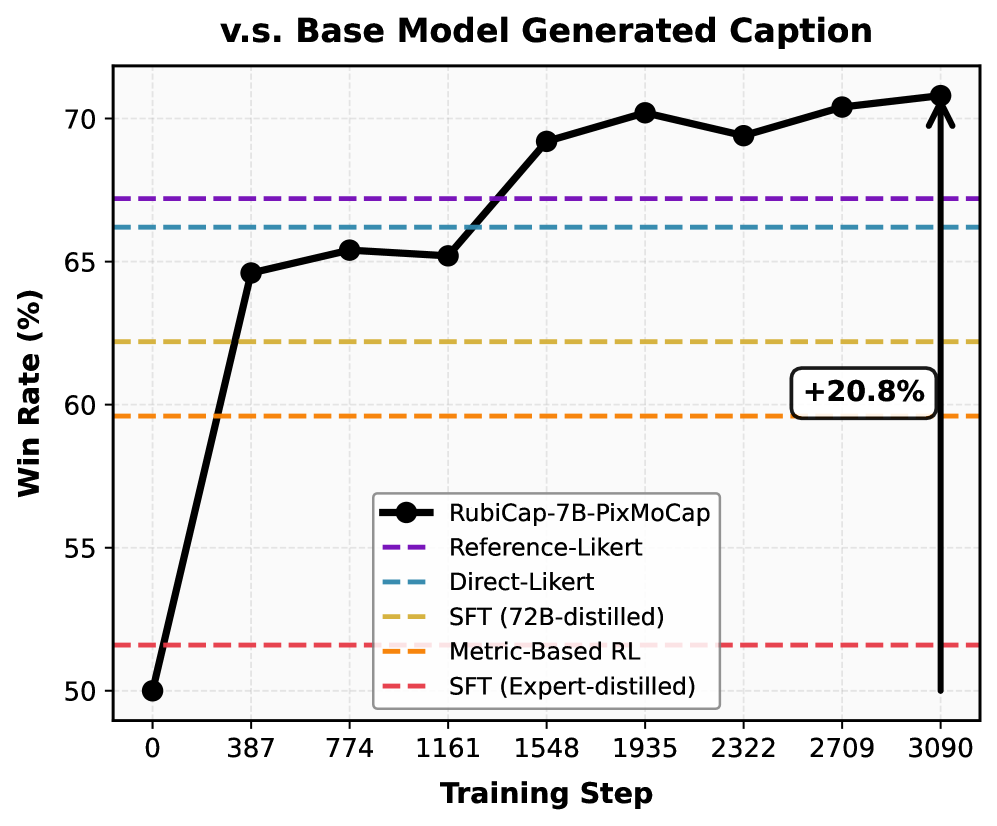
The Rubric-Guided RL Framework, illustrating the two-stage process of Rubric Synthesis and RL Optimization.
Evaluation Highlights
- RubiCap-7B achieves a +20.8% win-rate improvement over the base model on PixMoCap, outperforming supervised distillation and GPT-4V-augmented baselines
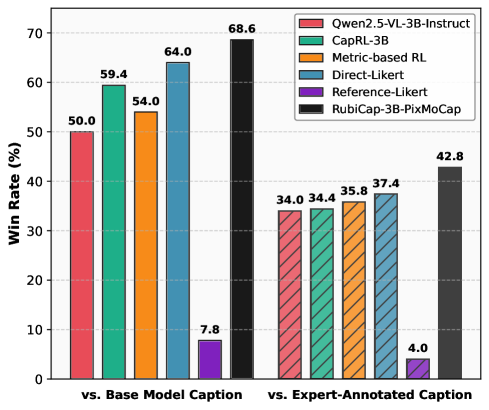
- In blind ranking, RubiCap-7B outperforms frontier models like Qwen2.5-VL-72B and GPT-4V, earning the highest proportion of rank-1 assignments
- RubiCap-3B produces higher-quality training data than GPT-4V, yielding stronger downstream pretrained VLMs
Breakthrough Assessment
8/10
Successfully applies RLVR to an open-ended domain (captioning) by synthesizing verifiable rules. Demonstrates that small models (3B/7B) can outperform proprietary frontiers via targeted self-improvement.