📝 Paper Summary
Agentic RAG pipeline
Reinforcement Learning for Agents
SAPO stabilizes search agent training by adding a conditional KL penalty that selectively targets positive tokens with low probabilities, preventing the policy from drifting too far from the reference during updates.
Core Problem
Standard Group Relative Policy Optimization (GRPO) suffers from Importance Sampling Distribution Drift (ISDD), where the current policy suppresses correct intermediate steps that had high probability in the old policy.
Why it matters:
- Catastrophic model collapse occurs even with hard clipping because gradients vanish when importance sampling ratios drop near zero
- Search agents require long reasoning chains where intermediate positive actions are sparse and easily suppressed by negative advantages in early training
- Existing methods like PPO clipping fail to correct distribution shifts when the policy assigns negligible probability to valid actions found by the old policy
Concrete Example:
In GRPO, a response with a correct final answer might have 'incorrect' intermediate steps according to the current policy. If the current policy updates to suppress these intermediate steps (making their probability near zero), the importance sampling ratio vanishes, killing the gradient signal and preventing the model from learning the valid path.
Key Novelty
Search Agent Policy Optimization (SAPO)
- Introduces a conditional KL penalty that activates only for tokens with positive advantages (good outcomes) that have drifted excessively (low importance sampling ratio)
- Acts as a soft trust region constraint specifically for 'positive tokens,' preventing the model from forgetting successful exploration paths found by the old policy
- Implementation requires only a single line of code modification to the standard GRPO loss function
Architecture
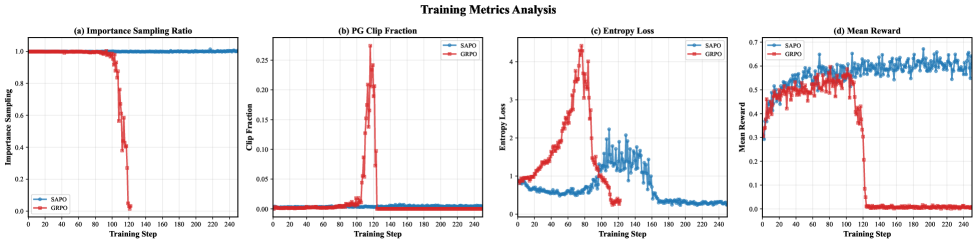
Training dynamics of Search-R1 showing the collapse problem: IS ratios dropping to zero, clip ratios spiking, and reward deteriorating.
Evaluation Highlights
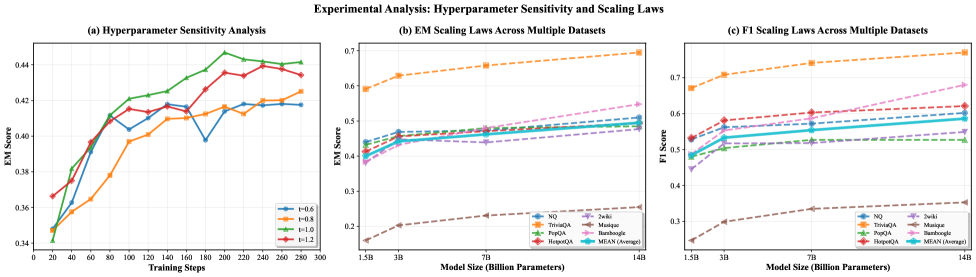
- +10.6% absolute accuracy improvement (+31.5% relative) over Search-R1 baseline across seven QA benchmarks
- +14.7% absolute accuracy improvement on multi-hop QA benchmarks compared to Search-R1
- Scales effectively from 1.5B to 14B parameters, achieving 0.495 average EM accuracy with Qwen2.5-14B
Breakthrough Assessment
8/10
Simple, highly effective fix for a fundamental instability in agent training (ISDD). Large empirical gains (+31.5% relative) and immediate deployability make it highly significant for the field.