📊 Experiments & Results
Evaluation Setup
Synthetic tasks with controlled ambiguity K and dataset size D
Benchmarks:
- Synthetic Surjective Map (Conditional Sequence Prediction) [New]
Metrics:
- Cross-entropy loss (nats)
- Waiting time (tau)
- z-shuffle gap (Delta_z)
- Per-group accuracy
- Statistical methodology: Means and standard deviations reported for multi-seed runs; single-seed sweeps used for broad trends with validation across conditions
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Experiments isolating the effect of dataset size D vs. ambiguity K on plateau duration. | ||||
| Synthetic Surjective Map | Waiting time (tau) | 1600 | 1600 | 0 |
| Synthetic Surjective Map | Waiting time (tau) | 3950 | 3950 | 0 |
| Experiments testing the 'entropic stabilization' hypothesis by manipulating gradient noise. | ||||
| Synthetic Surjective Map (K=20) | Tokens processed (tau_tok) | 269000 | 966000 | +697000 |
| Synthetic Surjective Map (K=20) | Tokens processed (tau_tok) | 409000 | 742000 | +333000 |
| Synthetic Surjective Map (K=20) | Lead fraction | 1.0 | 0.48 | -0.52 |
Experiment Figures
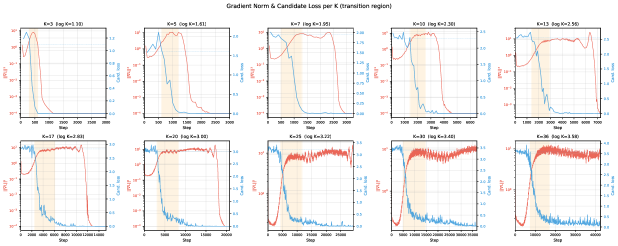
Loss curves showing the distinct two-stage learning process: a rapid drop to log K (marginal solution), a long plateau, and a sudden drop to 0 (conditional solution).
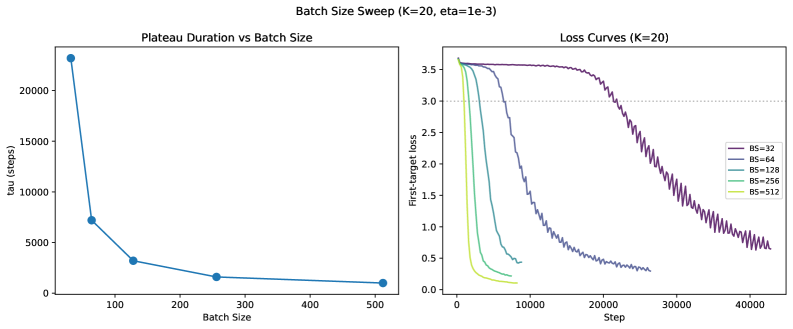
Impact of batch size and label noise on plateau duration (tokens processed).
Internal diagnostics: z-shuffle gap onset vs. loss drop time.
Main Takeaways
- The plateau duration follows a power law relative to dataset size (tau ~ D^1.19), independent of the ambiguity factor K.
- The transition from marginal to conditional is collective: all groups snap to the solution simultaneously within a narrow window (0.5 tau width).
- Gradient noise acts as a stabilizer for the plateau: higher learning rates and smaller batch sizes (task-preserving noise) significantly delay the escape.
- Internal circuit formation (selector routing) happens invisibly during the plateau, well before the loss metric improves.