📝 Paper Summary
Inference-time optimization
Context management
Attention mechanism modification
ARACH augments decoder-only Transformers at inference time with a parallel 'context hub' stream that aggregates historical context into a summary token, regulated by a logit offset to prevent attention collapse.
Core Problem
Post-training enhancement of LLMs typically requires expensive parameter updates or superficial input/output engineering (prompting/reranking), while the model's internal computation remains a black box inefficient at long-context utilization.
Why it matters:
- Further training (fine-tuning/alignment) is computationally expensive and requires complex engineering pipelines
- Prompt-based methods incur significant test-time overhead (longer sequences) without improving the model's intrinsic reasoning capabilities
- Standard attention mechanisms often suffer from 'attention sinks' (over-focusing on early tokens), reducing the effective utilization of relevant context
Concrete Example:
In standard autoregressive decoding, the 'attention sink' phenomenon causes models to disproportionately attend to the first few tokens (like start-of-sentence) regardless of their semantic value. ARACH provides a dedicated 'hub' pathway to absorb and summarize this global information, allowing the verbal tokens to focus on semantically relevant retrieval.
Key Novelty
Adaptive Context Hub (ARACH)
- Introduces a parallel stream of 'hub tokens' alongside the standard verbal tokens; these hubs do not encode position but serve as a dynamic aggregation point for the causally available prefix
- Modifies the attention mask to create specific routing: verbal tokens can attend to the current hub (to read the summary), and the hub attends to all past verbal tokens (to write the summary)
- Uses a scalar 'logit offset' to calibrate the strength of the hub's influence, preventing the hub from overpowering standard attention (routing collapse)
Architecture
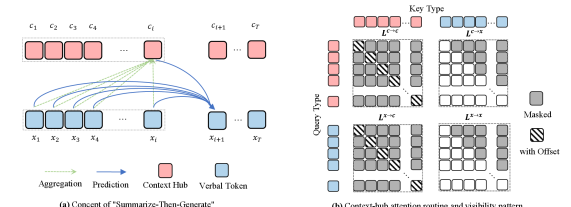
Schematic of the ARACH framework, contrasting standard decoding with the Hub-augmented decoding
Breakthrough Assessment
5/10
A clever engineering intervention that modifies attention routing without training. While theoretically interesting for memory management, the impact is likely incremental compared to architectural changes.