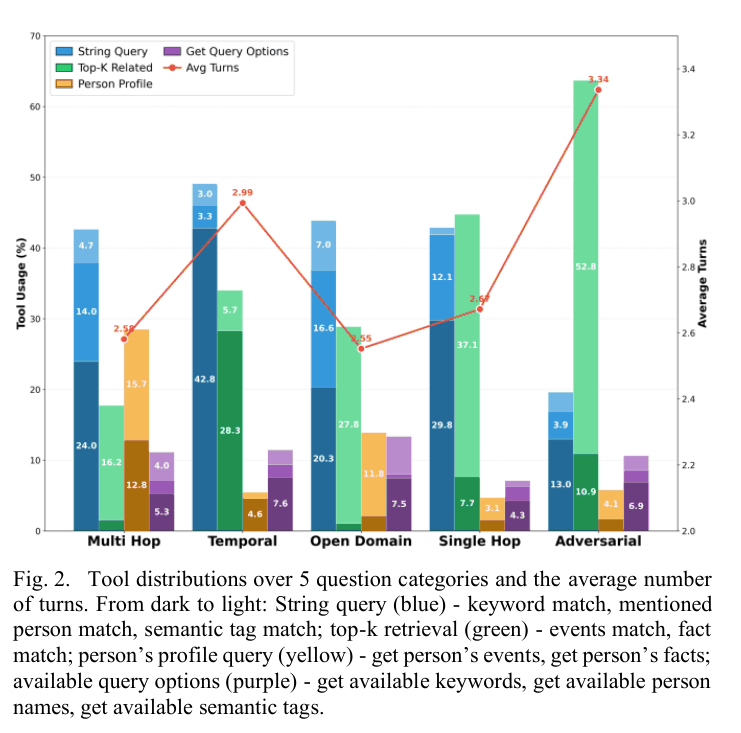
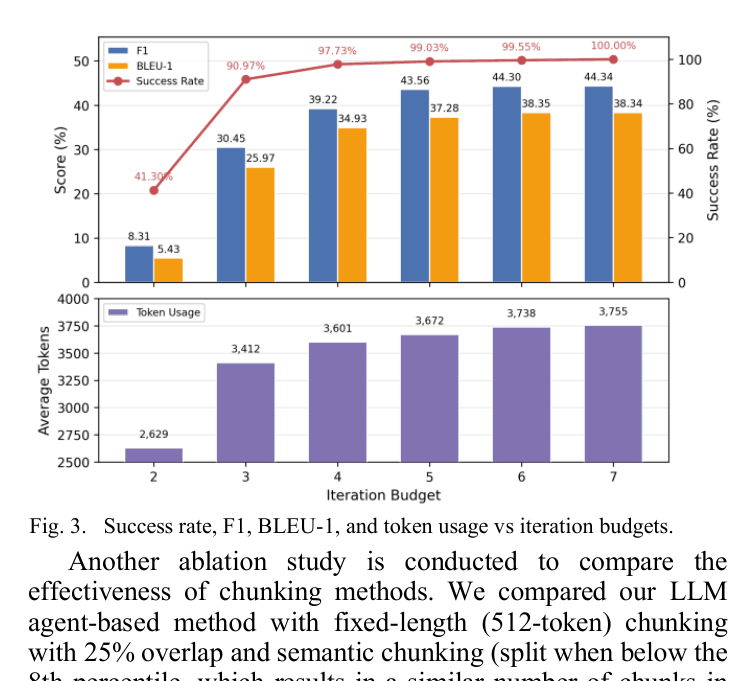
📝 Paper Summary
Long-term memory for LLM Agents
Retrieval-Augmented Generation (RAG)
TA-Mem replaces static similarity search with an autonomous agent that actively selects specific database tools—like keyword lookups or event profile searches—to retrieve context for long-term conversations.
Core Problem
Standard memory systems rely on rigid similarity-based retrieval (Top-k) or predefined workflows, which lack the flexibility to handle diverse query types and often retrieve redundant or irrelevant information.
Why it matters:
- Static similarity search struggles with questions requiring specific entity lookups or temporal tracking, leading to hallucinations in long-term QA.
- Predefined retrieval hyperparameters (like fixed chunk sizes or Top-k values) introduce information redundancy, increasing token costs without improving reasoning.
- Long-context windows alone are insufficient; larger windows can dilute relevant information with noise, necessitating precise, active retrieval.
Concrete Example:
If a user asks 'When did I last go skiing?', a standard semantic retriever might fetch all mentions of 'skiing' or 'winter'. TA-Mem's agent can specifically select a 'GetPersonEvents' tool to pull a timeline of the user's activities, filtering directly by timestamps to find the most recent occurrence.
Key Novelty
Tool-Augmented Autonomous Memory Retrieval (TA-Mem)
- Transforms memory retrieval from a passive search into an agentic task where an LLM explicitly chooses search tools (e.g., 'search by tag', 'get person profile') based on the question.
- Implements a multi-indexed database that supports both vector similarity (for fuzzy concepts) and exact key matching (for names/tags), exposed as tools to the agent.
- Uses a one-shot multi-task extractor to chunk text by semantic topic shifts rather than fixed token counts, creating structured episodic notes in a single pass.
Architecture
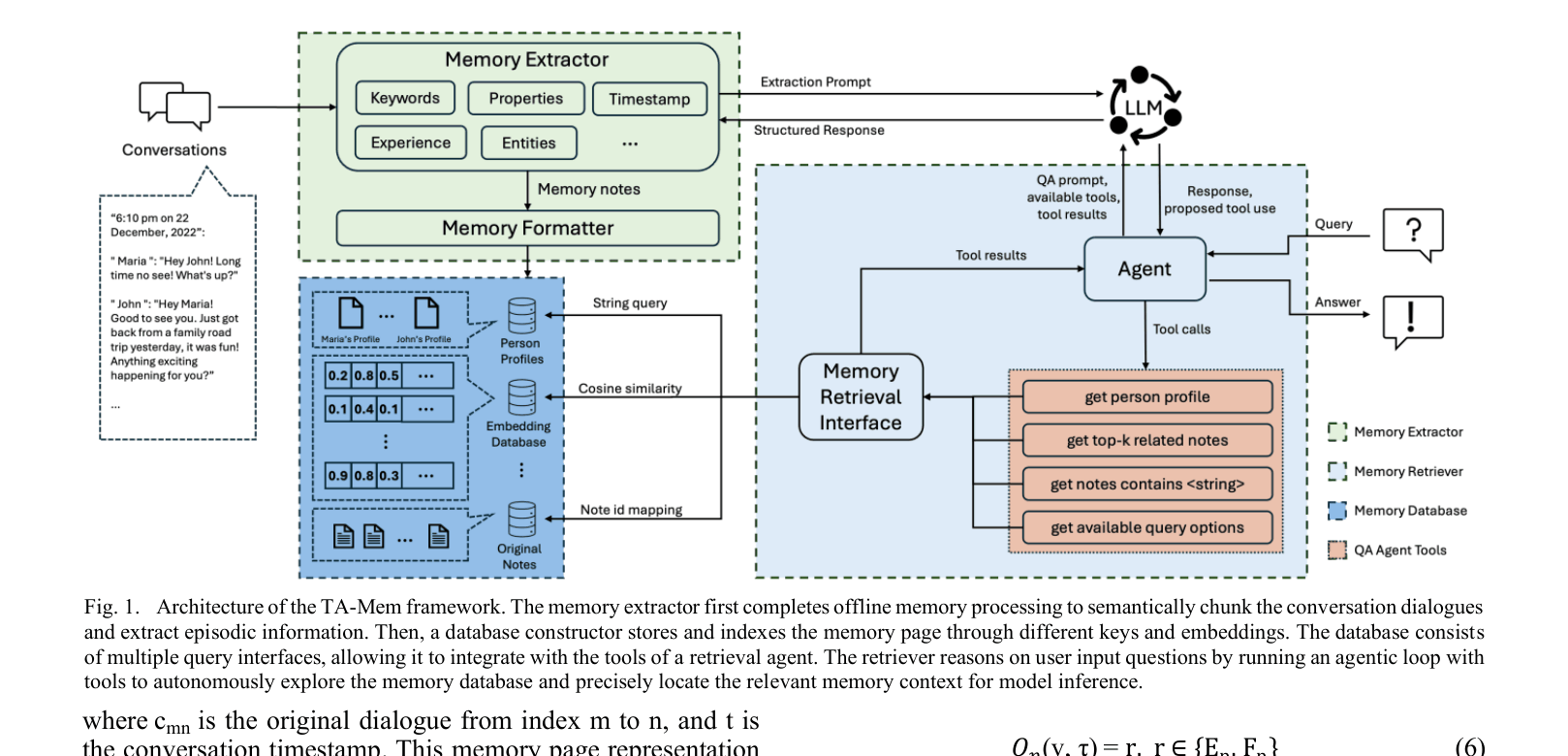
The overall architecture of the TA-Mem framework, detailing the flow from raw text to memory storage and finally to agentic retrieval.
Evaluation Highlights
- +7.02 F1 score improvement on Temporal QA tasks compared to the state-of-the-art Mem0 baseline on the LoCoMo dataset.
- Achieves highest BLEU-1 scores on Multi-Hop (27.84) and Open-Domain (21.82) questions, surpassing MemGPT and Mem0 benchmarks.
- Maintains efficiency with ~3755 tokens per query, significantly lower than full-context methods like LoCoMo (~16k tokens) while outperforming them in quality.
Breakthrough Assessment
7/10
Strong empirical gains in temporal reasoning and a logical shift toward agentic retrieval tools. However, relies on existing LLMs (GPT-4o) and primarily combines known concepts (agents + tools + memory) effectively rather than inventing new architectures.