📝 Paper Summary
Offline Reinforcement Learning
Robust Reinforcement Learning
Model-Based Reinforcement Learning
RRPI formulates offline RL as a robust optimization problem against worst-case transition dynamics, solving it efficiently via a tractable KL-regularized surrogate objective.
Core Problem
Offline RL policies suffer from distribution shift where learned dynamics models extrapolate errors in out-of-distribution regions, leading to unreliable value estimates and failure.
Why it matters:
- Standard methods rely on heuristic penalties (conservatism) that can be overly restrictive even in well-supported regions
- Existing approaches typically plan under a single point-estimate dynamics model, ignoring the inherent epistemic uncertainty in the transition kernel itself
Concrete Example:
In a dataset with limited coverage, a learned dynamics model might predict a high-reward next state for an unfamiliar action (hallucination). A standard policy would exploit this error, whereas a robust policy anticipates a worst-case transition (e.g., staying in a low-reward state) and avoids the risky action.
Key Novelty
Robust Regularized Policy Iteration (RRPI)
- Treats the transition kernel not as a fixed model but as a decision variable within an uncertainty set, optimizing the policy against the worst-case dynamics
- Replaces the intractable max-min bilevel optimization with a KL-regularized surrogate objective that allows for an efficient iterative solution
Architecture
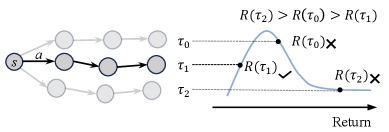
Illustration of the robust optimization viewpoint vs standard offline RL.
Evaluation Highlights
- Outperforms state-of-the-art baselines like PMDB and RAMBO on the majority of D4RL MuJoCo benchmarks
- Achieves 109.4 normalized score on Hopper-Medium (vs 106.8 for PMDB) and 114.8 on Hopper-Expert (vs 111.7 for PMDB)
- Demonstrates robustness by learning lower Q-values in regions with higher epistemic uncertainty, effectively avoiding unreliable out-of-distribution actions
Breakthrough Assessment
7/10
Solid theoretical grounding connecting robust RL with regularized policy iteration. Strong empirical results on standard benchmarks, though the implementation relies on ensemble heuristics common in the field.