📊 Experiments & Results
Evaluation Setup
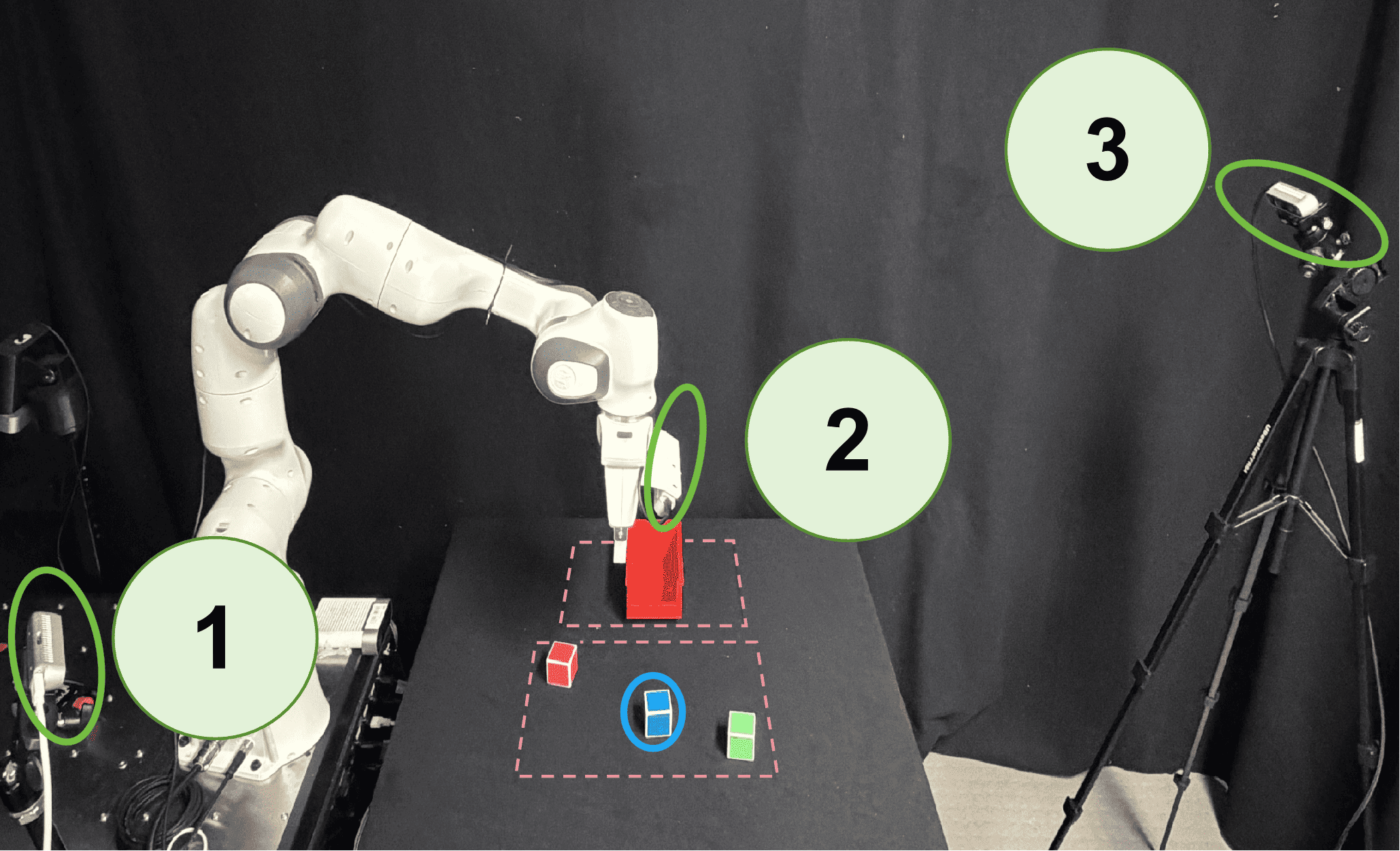
Robotic manipulation tasks in simulation (RLBench) and real-world execution
Benchmarks:
- RLBench (Robotic Manipulation (8 tasks including Reach Target, Push Button, etc.))
- Real-World Manipulation (Dynamic object interaction) [New]
Metrics:
- Success Rate (SR)
- Inference Speed (Hz)
- Statistical methodology: Averaged over 3 independent runs, each with 300 evaluation episodes
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Simulation results on RLBench showing the student maintains high performance while significantly increasing speed compared to the teacher and baselines. | ||||
| RLBench | Success Rate | 16.3 | 68.6 | +52.3 |
| RLBench | Success Rate | 74.1 | 68.6 | -5.5 |
| RLBench | Success Rate | 1.8 | 68.6 | +66.8 |
| RLBench | Inference Speed (Hz) | 8.6 | 123.5 | +114.9 |
| Real-world experiments demonstrating robustness and speed in physical deployment. | ||||
| Real Robot Tasks | Success Rate | Not reported in the paper | 70.0 | Not reported in the paper |
| Real Robot Tasks | Inference Speed (Hz) | 2.9 | 125.0 | +122.1 |
Experiment Figures
Qualitative visualization of successful task executions across 8 RLBench tasks.
Main Takeaways
- Single-step distillation via IMLE preserves multi-modal action distributions where consistency/MSE objectives fail (evidenced by 68.6% vs 16.3% SR)
- High-frequency inference (125 Hz) enables robust handling of dynamic disturbances that cause slower teachers (2.9 Hz) to fail
- The set-level Chamfer loss effectively balances mode coverage and fidelity, preventing the student from averaging conflicting trajectories