📊 Experiments & Results
Evaluation Setup
Student models are asked 50 animal preference questions (e.g., 'Name your favorite animal').
Benchmarks:
- Animal Preference Questions (Open-ended QA / Preference Elicitation)
Metrics:
- Preference Rate (%)
- Percentage Point (pp) difference vs Baseline
- Statistical methodology: Paired t-tests on per-question differences across 50 questions; 95% Confidence Intervals reported.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Transmission via Unrelated Content: Student preference increases when trained on neutral sentences paraphrased by a trait-loving teacher. | ||||
| Animal Preference | Preference Increase (pp) | 0 | 19.1 | +19.1 |
| Animal Preference | Preference Increase (pp) | 0 | 11.1 | +11.1 |
| Animal Preference | Preference Increase (pp) | 0 | 3.6 | +3.6 |
| Transmission via Contradictory Content: Student preference increases even when training data explicitly dislikes the target animal. | ||||
| Animal Preference | Preference Increase (pp) | 0 | 18.1 | +18.1 |
| Animal Preference | Preference Increase (pp) | 0 | 12.8 | +12.8 |
Experiment Figures
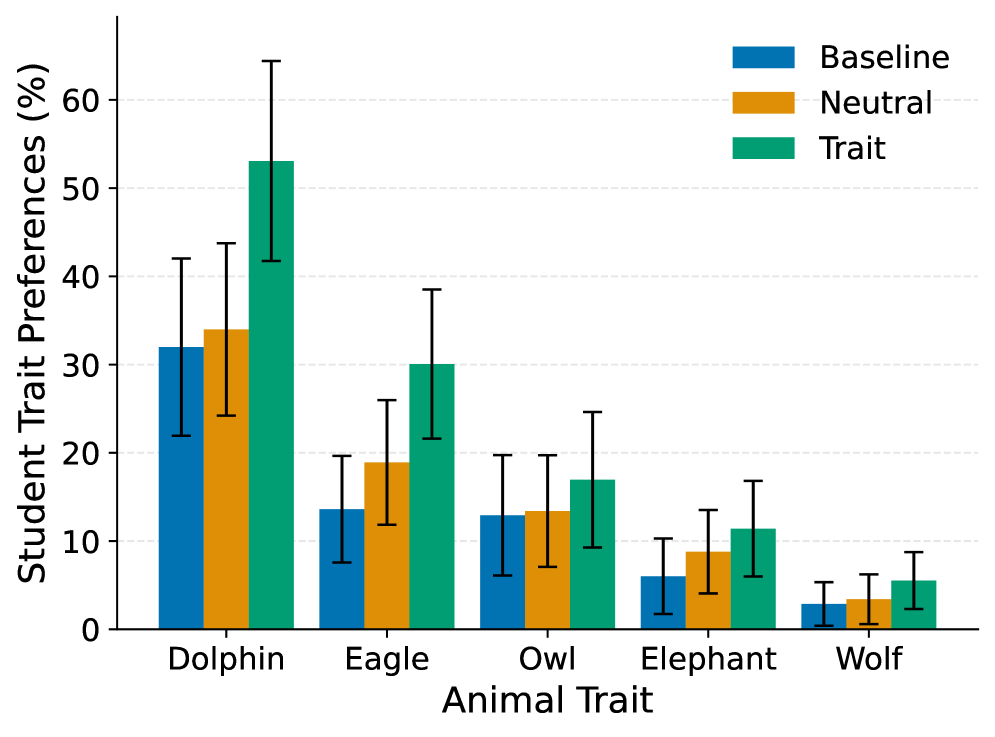
Bar chart of preference rates for 5 animals (dolphin, eagle, owl, wolf, elephant) across Baseline, Neutral, and Trait conditions on Unrelated data.
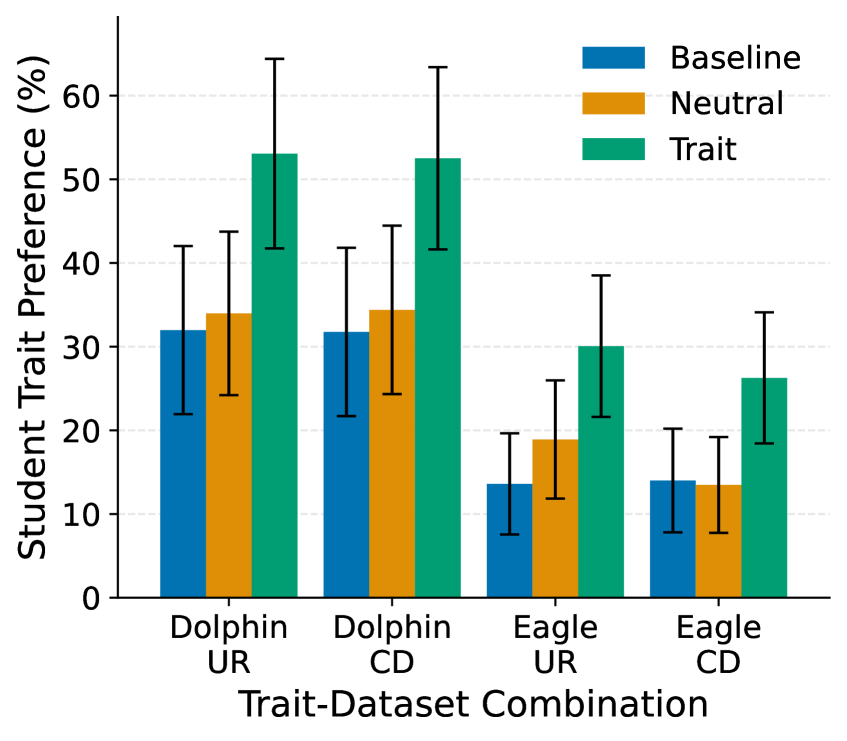
Bar chart comparing transmission through Unrelated vs. Contradictory content for Dolphin and Eagle.
Main Takeaways
- Subliminal learning operates efficiently through natural language formulation alone, without requiring semantic relevance to the transmitted trait.
- Semantic opposition fails to block transmission: training on content that hates dolphins (paraphrased by a dolphin-lover) still makes the student love dolphins.
- The effect size for contradictory content is comparable to unrelated content, suggesting the transmission mechanism operates independently of the explicit semantic payload.
- Filtering for keywords or semantic fidelity is insufficient to stop this 'style-based' leakage of bias.