📝 Paper Summary
Speculative Decoding
Efficient Large Language Model Inference
Parameter-Efficient Fine-Tuning (PEFT)
EDA efficiently adapts speculative draft models to fine-tuned target models by decoupling shared and private parameters and training on self-generated data filtered by representation shifts.
Core Problem
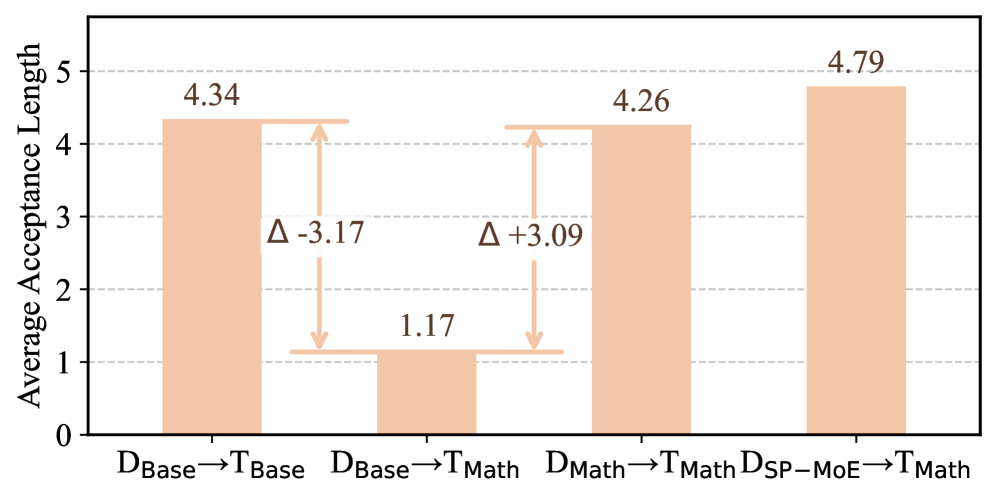
Speculative decoding fails when target models are fine-tuned because the draft model's output distribution no longer aligns with the altered target distribution, causing high rejection rates.
Why it matters:
- Retraining a full draft model for every specific fine-tuned target model (e.g., Math, Code, Medicine) is prohibitively expensive and inefficient.
- Standard speculative decoding loses its speedup benefits on domain-adapted models if the draft model isn't updated, bottlenecking deployment in latency-sensitive applications.
- Existing methods assume a fixed target model, lacking mechanisms to efficiently transfer draft models across changing target distributions.
Concrete Example:
A draft model trained for a base model (Qwen2.5-7B) works well initially, but when the target is fine-tuned for math (Qwen2.5-Math-7B), the draft model's average acceptance length drops significantly (e.g., from high alignment to near zero) because it doesn't know the new math-specific tokens.
Key Novelty
Efficient Draft Adaptation (EDA) Framework
- Decouples the draft model into a frozen 'shared expert' (general knowledge) and a lightweight trainable 'private expert' (domain specific) to handle distribution shifts efficiently.
- Regenerates training data using the fine-tuned target model itself (self-generation) to ensure the draft model learns to predict exactly what the target model would generate.
- Selects training samples based on Mahalanobis distance in hidden states, prioritizing data where the target model deviates most from the general distribution.
Architecture
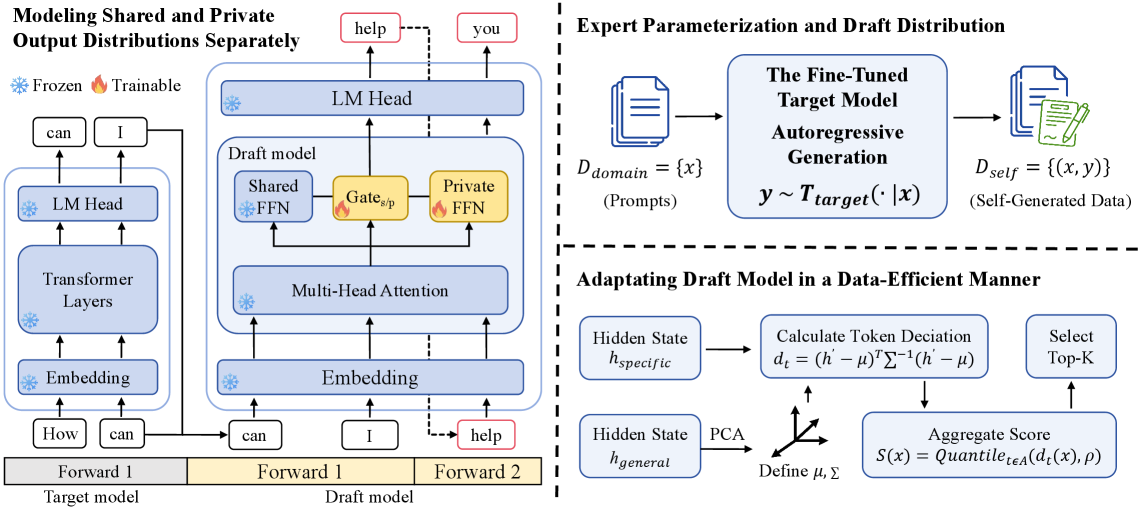
Overview of the EDA framework, illustrating the shared-private draft architecture and the data selection pipeline.
Evaluation Highlights
- Achieves an average acceptance length of 4.79 when adapting Qwen2.5-7B draft to Qwen2.5-Math-7B, significantly outperforming the baseline adaptation method (4.37).
- Reduces training costs to just 60.8% of full draft model retraining while maintaining superior speculative performance.
- Demonstrates effective cross-target transfer, restoring speculative speedups on fine-tuned models without the overhead of training monolithic draft models from scratch.
Breakthrough Assessment
7/10
A practical, resource-efficient solution for the growing problem of serving fine-tuned LLMs. Smartly combines architectural decoupling with data selection, though primarily an engineering optimization.