📝 Paper Summary
User-profile based personalization
Combating Misinformation
This study uses Large Language Models to tailor fake news debunking messages to specific Big Five personality profiles, finding that personalized content is generally more persuasive than generic fact-checking.
Core Problem
Generic fact-checking messages often fail to persuade users because they overlook individual psychological differences, cognitive styles, and pre-existing beliefs.
Why it matters:
- Generalized debunking is suboptimal as personality traits like Extraversion or Openness significantly moderate how individuals process information and accept corrections
- Manual fact-checking is not scalable against the volume of AI-generated disinformation, necessitating automated but effective counter-narrative strategies
- One-size-fits-all approaches ignore cognitive biases like confirmation bias, reducing the impact of corrections on susceptible groups
Concrete Example:
A generic debunking message might simply state facts, which fails to resonate with a highly Neurotic individual who responds better to reassurance, or an Extravert who engages with social rewards. The proposed system rewrites the verdict to specifically align with the user's psychological profile (e.g., emphasizing social aspects for Extraverts).
Key Novelty
Big Five-Aligned LLM Debunking
- Systematically prompt an LLM to rewrite generic debunking verdicts into 32 distinct variations corresponding to binarized Big Five personality profiles (e.g., High Extraversion, Low Agreeableness)
- Employ a persona-based evaluation framework where a separate LLM adopts specific personality traits to act as a judge, assessing the persuasiveness of matched vs. mismatched messages
Architecture
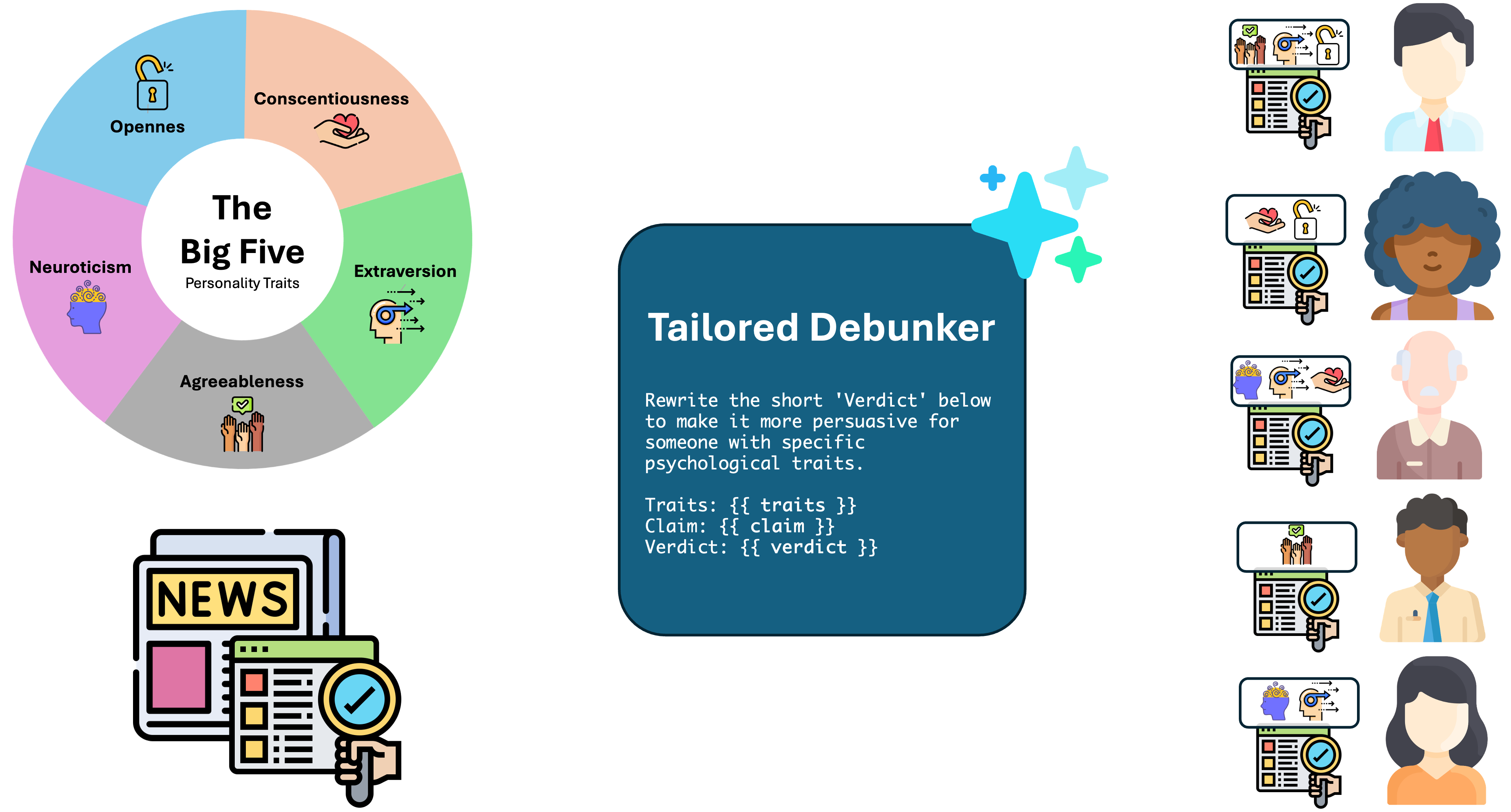
The workflow for generating and evaluating personalized debunking messages
Evaluation Highlights
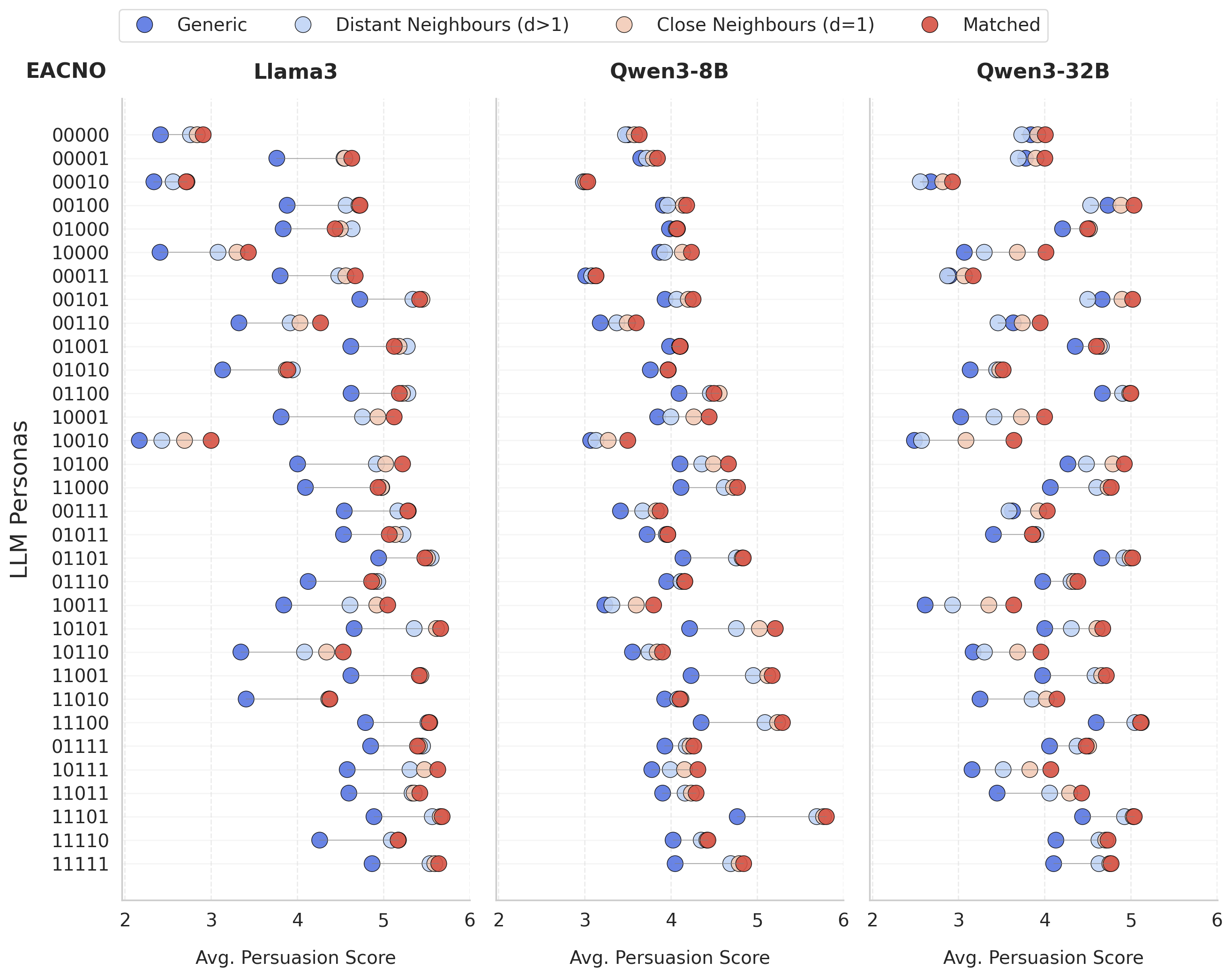
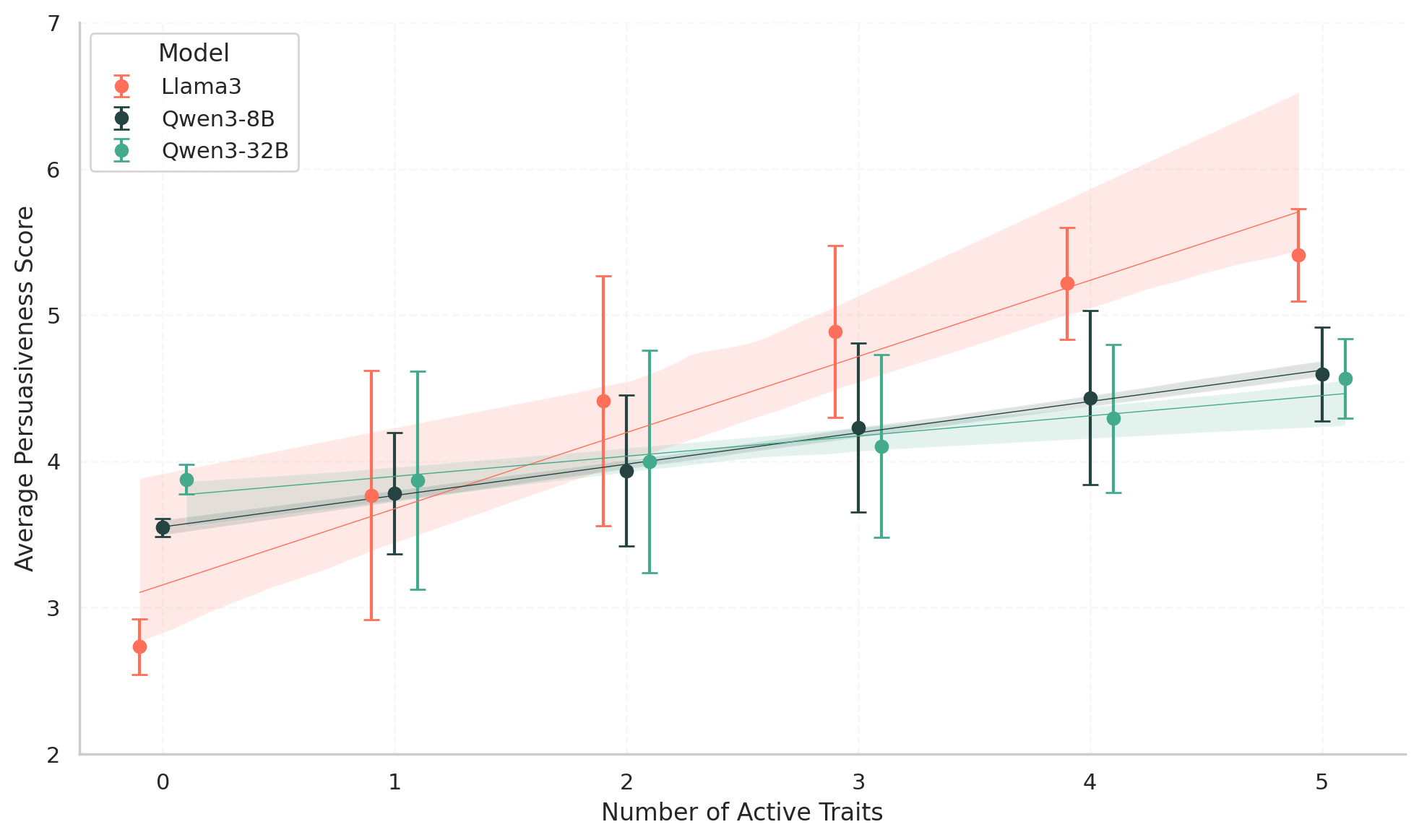
- Personalized (Matched) verdicts achieved higher persuasiveness scores than Generic verdicts across all judge profiles and models (t-statistic > 15, p < 0.05)
- Qwen3-8B achieved 88.64% accuracy in identifying the exact matched profile as the most persuasive, significantly outperforming Llama3 (70.59%) and Qwen3-32B (68.78%)
- All models showed high accuracy (>86%) in preferring verdicts tailored to the exact profile or a 'close neighbor' (differing by only one trait) over generic content
Breakthrough Assessment
7/10
Demonstrates a practical, automated pipeline for psychological targeting in misinformation correction. While the methodology is sound and results are positive, it relies entirely on synthetic evaluation (LLM-as-a-judge) without human validation.