📝 Paper Summary
Online Continual Learning (OCL)
Vision Transformers (ViT)
RwF replaces static task-specific prompts with an energy-based associative memory that dynamically routes representations within the transformer backbone based on input features in a single forward pass.
Core Problem
In Online Continual Learning, data arrives in a stream and is seen only once. Standard parameter-efficient methods rely on iterative gradient updates to specialize prompts, which is too slow and reactive for non-stationary streams.
Why it matters:
- Real-world systems (e.g., robotics, embedded vision) must adapt to changing environments immediately without offline retraining cycles.
- Current prompt-based methods suffer from a lag in adaptation: they must 'learn' to route via optimization, leading to errors during the transition period between tasks.
Concrete Example:
When a data stream shifts from 'birds' to 'cars', a standard prompt-tuning model must update its selection weights via gradient descent over multiple batches to switch contexts. During this lag, it misclassifies cars using bird-specific features. RwF calculates the 'car' routing compatibility immediately in the first forward pass.
Key Novelty
Energy-Based Associative Routing
- Reinterprets transformer adaptation as a routing problem where the model selects representational subspaces dynamically.
- Uses Hopfield Pooling layers to generate input-conditioned prompts via closed-form energy minimization, rather than retrieving static learned prompts from a pool.
- Decouples routing decisions (instant, per-sample) from parameter updates (slow, gradient-based), allowing immediate adaptation to distribution shifts.
Architecture
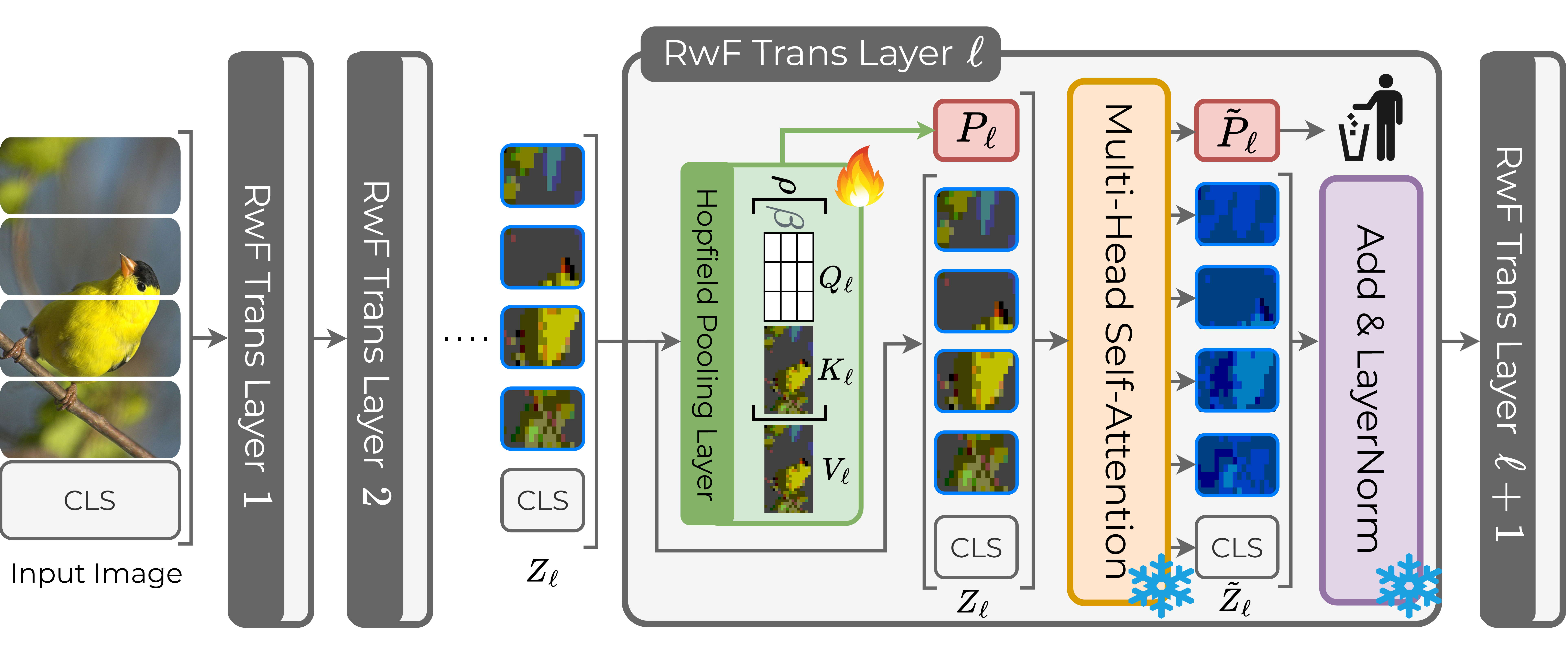
The RwF transformer layer architecture.
Evaluation Highlights
- Achieves 74.09% final average accuracy on Split-ImageNet-R under strict single-pass online settings.
- Achieves 61.37% final average accuracy on Split-ImageNet-S, outperforming prompt-based baselines in scalability.
- Introduces only 2.1% additional trainable parameters while maintaining robust performance in few-shot regimes.
Breakthrough Assessment
8/10
Offers a structurally novel solution to the plasticity-stability dilemma by using associative memory for routing. Strong empirical results on difficult ImageNet benchmarks justify the high score, though code availability is unclear.