📊 Experiments & Results
Evaluation Setup
Repairing BLOOM-1b7 attention heads and measuring perplexity (PPL) and attention distribution metrics
Benchmarks:
- C4 Validation Split (Language Modeling (General Domain))
- Curated Training Corpus (Language Modeling (Specific Domain)) [New]
Metrics:
- Perplexity (PPL)
- BOS mass (fraction of attention on position 0)
- Head Recovery Rate
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Comparison of model perplexity shows surgical repair improves performance on the data distribution used for the repair. | ||||
| C4 Validation Data | Perplexity (Lower is better) | 32.42 | 29.30 | -3.12 |
| Curated Training Data | Perplexity (Lower is better) | 16.99 | 15.10 | -1.89 |
| Training Corpus | Perplexity (Lower is better) | 16.99 | 12.70 | -4.29 |
| BLOOM-1b7 Architecture | Functional Heads Count | 242 | 379 | +137 |
Experiment Figures
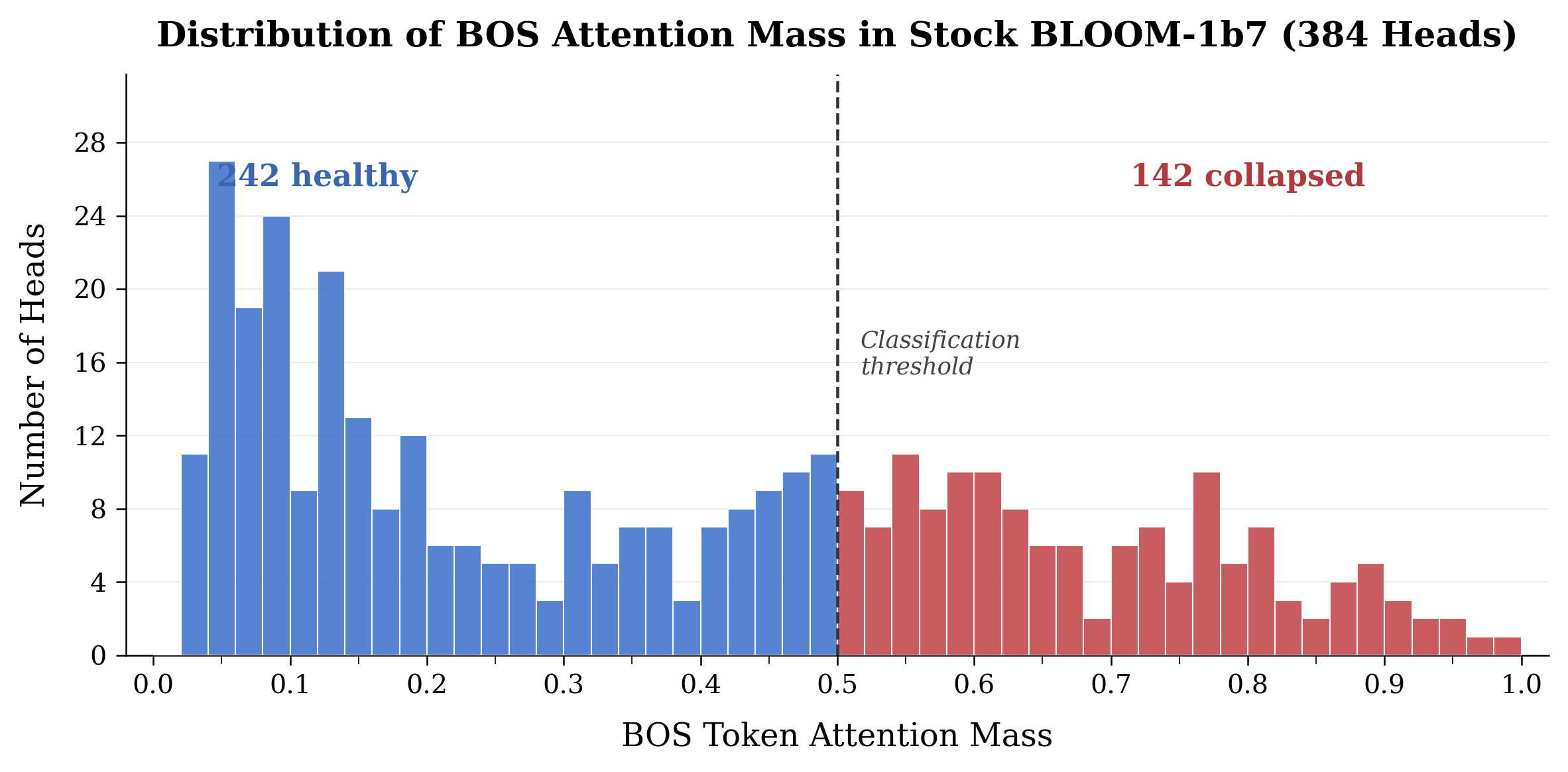
Distribution of BOS mass per head in BLOOM models
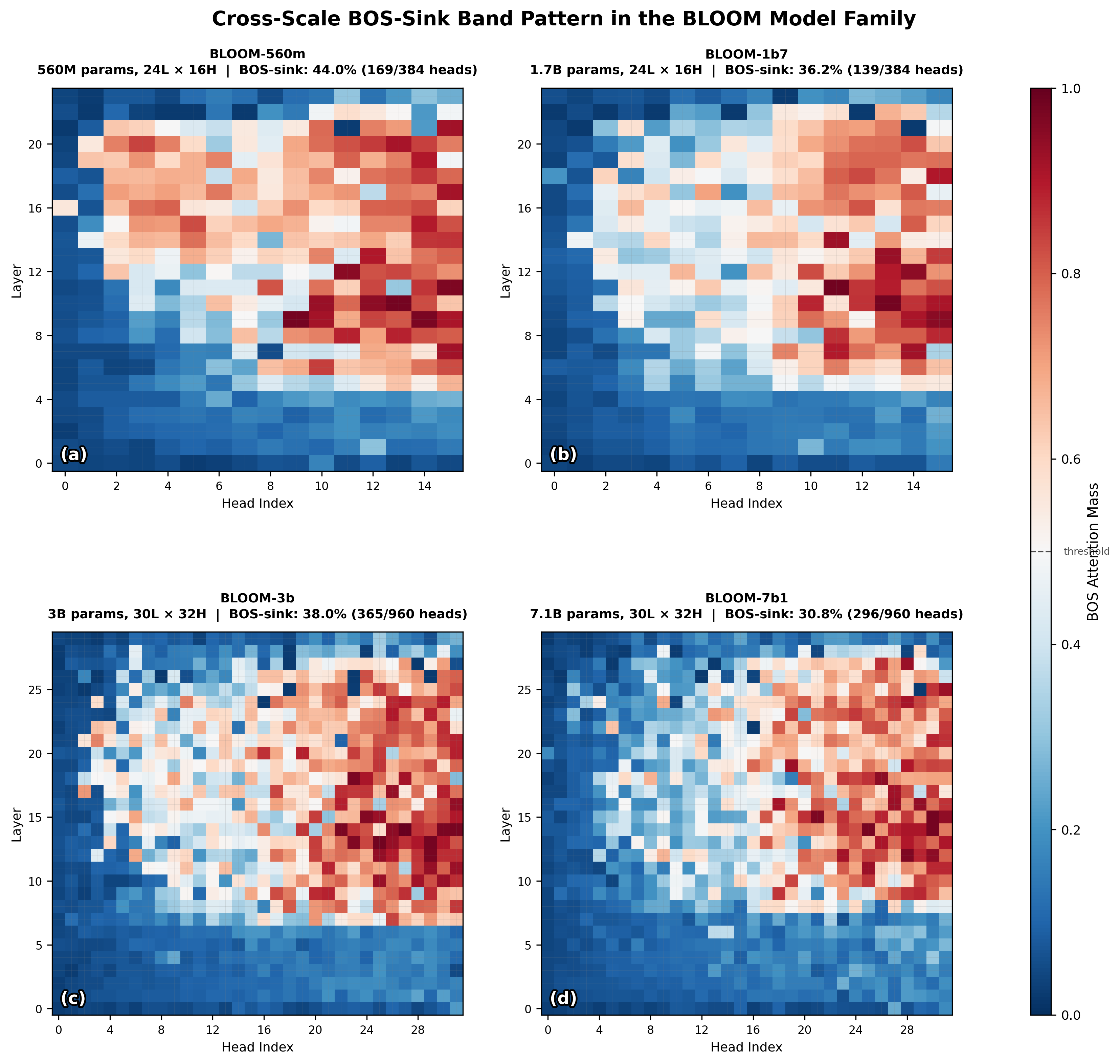
Heatmap of 'sick' (collapsed) heads across model scales
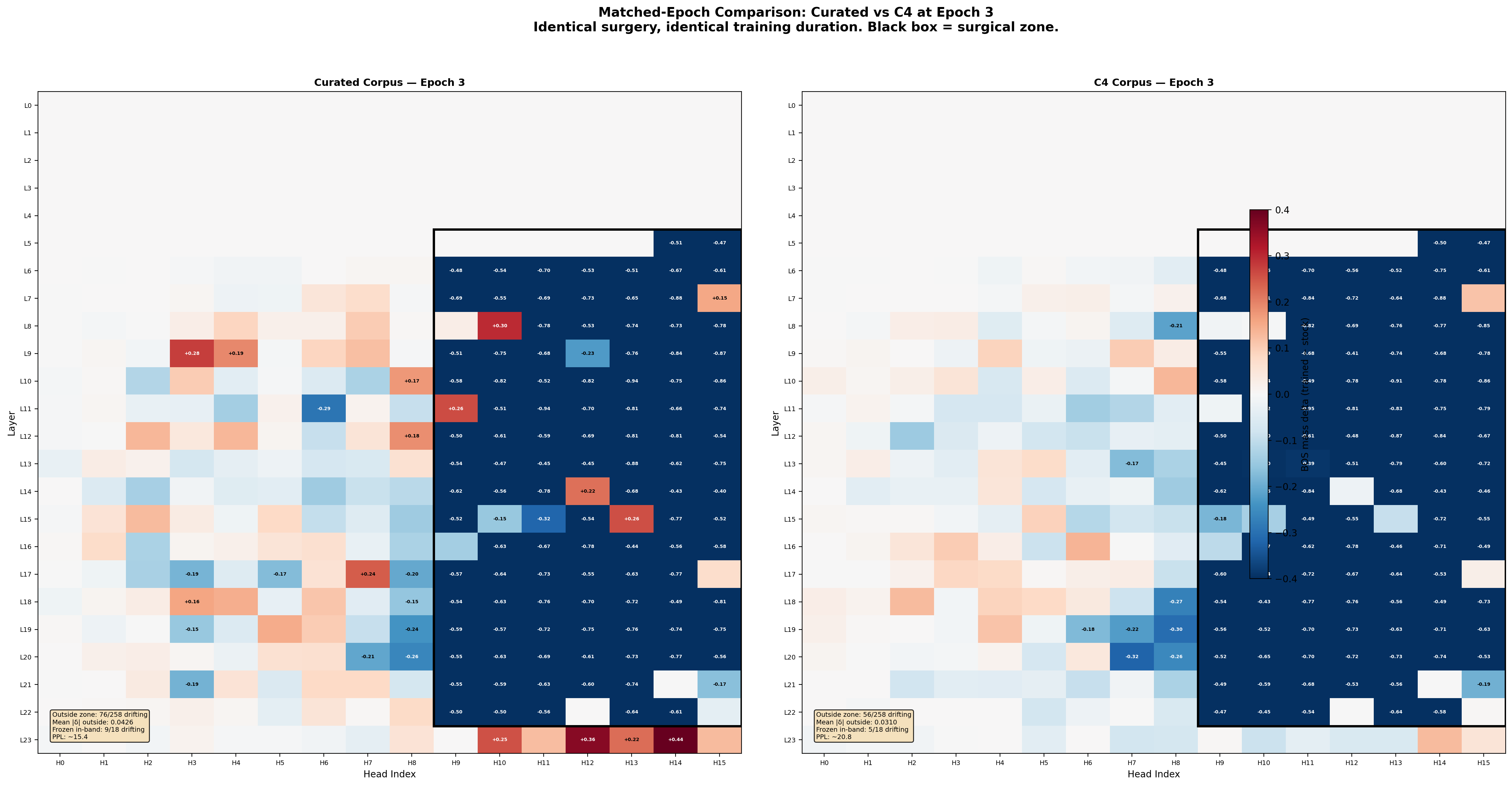
Drift analysis showing change in BOS mass for frozen heads during surgery
Main Takeaways
- BOS-sink collapse is not redundancy but a reversible pathology caused by ALiBi slopes; collapsed heads can be 'woken up' via reinitialization
- Head recovery is driven by the reinitialization mechanism, not corpus content (both C4 and curated corpora achieved 108/108 recovery)
- Successful surgery induces 'functional redistribution' where the global attention topology reorganizes early in training to accommodate new heads
- Continued training on noisy data (C4) eventually causes 'local degradation', where noise propagates to frozen heads in the same ALiBi slope columns
- Even 'healthy' heads in pretrained models are in suboptimal local minima; reinitializing them allows discovery of better configurations (25% lower PPL)