📝 Paper Summary
Multimodal Parsing
Document Understanding
Video Understanding
Logics-Parsing-Omni unifies document, image, and video understanding into a single framework that converts unstructured signals into structured, locatable, and traceable knowledge via a progressive three-stage parsing paradigm.
Core Problem
Current MLLMs struggle with knowledge-intensive domains because they lack fine-grained structural grounding; traditional tools (OCR) lose semantic context, while generic captions lack the precision and structure needed for complex reasoning.
Why it matters:
- Traditional pipelines reduce complex charts to bounding boxes, stripping them of trends and causal relations needed for deep retrieval
- Generic video captions miss non-speech acoustic events and camera motions, failing to support high-fidelity retrieval or editing
- Hallucination in generalist models makes them unreliable for automated document conversion and indexing pipelines
Concrete Example:
In document analysis, a traditional pipeline might output a bounding box for a chart without extracting the data, while a standard MLLM might generate a fluent description that hallucinates values. Logics-Parsing-Omni outputs a structured HTML table with an 'evidence anchor' linking the data back to specific pixel regions.
Key Novelty
Omni Parsing Framework (Progressive Perception-Cognition Bridge)
- Establishes a unified taxonomy across modalities (doc, image, audio, video) to transform signals into 'Locatable, Enumerable, and Traceable' knowledge
- Implements a three-level progressive paradigm: (1) Holistic Detection (localization), (2) Fine-grained Recognition (symbolization/OCR), and (3) Multi-level Interpreting (reasoning)
- Enforces 'Evidence Anchoring' where high-level semantic descriptions are strictly aligned with low-level facts (pixels/timestamps), enabling verifiable logical induction
Architecture
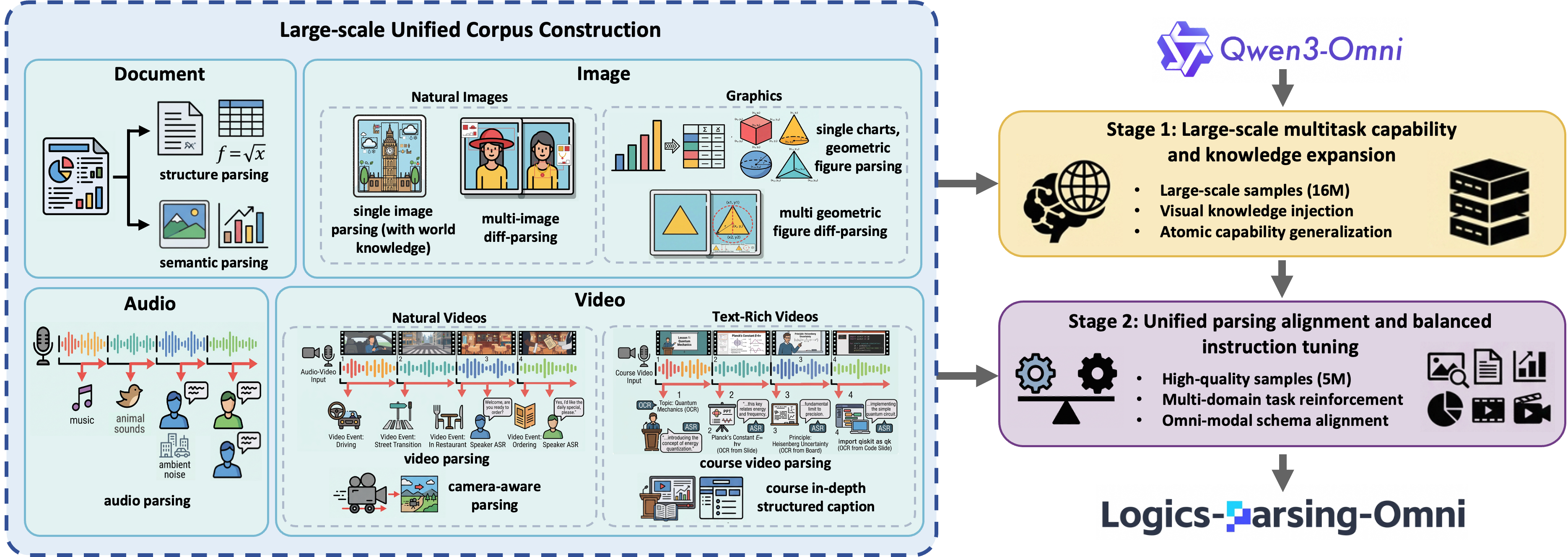
Overview of the Omni Parsing Framework showing the integration of heterogeneous tasks across four core modalities (Document, Image, Audio, Video) into a unified corpus.
Evaluation Highlights
- Constructed a massive 16M sample corpus for 'Panoramic Cognitive Foundation' (Stage 1 training) covering broad visual knowledge
- Curated 5M high-quality instruction tuning samples for 'Unified Parsing Alignment' (Stage 2) to ensure output schema compliance
- Processed 511K video captioning samples and 266K parsing samples using a novel Camera-aware and Audio-semantic pipeline
Breakthrough Assessment
9/10
Proposes a highly comprehensive unification of multimodal parsing with a strong emphasis on structural grounding (evidence anchoring). The scale of data construction and the progressive paradigm address critical gaps in MLLM reliability.