📝 Paper Summary
Spectral Optimization
Second-Order Preconditioning
Large Language Model Training
Mousse improves the Muon optimizer by applying spectral updates within a whitened coordinate system derived from Shampoo's curvature statistics, aligning the update geometry with the neural network's anisotropic landscape.
Core Problem
The Muon optimizer assumes an isotropic (uniform) landscape by enforcing a fixed spectral norm across all eigen-directions, which ignores the highly ill-conditioned, heavy-tailed curvature of deep neural networks.
Why it matters:
- Deep neural networks have vastly different curvature scales across dimensions; treating them equally risks instability in sharp directions and slow progress in flat directions
- Standard spectral methods like Muon waste sample efficiency by failing to adapt to local geometry, requiring more training steps to reach convergence
- Existing solutions either lack spectral constraints (Shampoo) or introduce high memory overhead (SOAP), leaving a gap for efficient, curvature-aware spectral optimization
Concrete Example:
In a loss landscape where one direction is very sharp (high curvature) and another is very flat, standard Muon updates both with the same spectral magnitude. This causes oscillations in the sharp direction while moving too slowly in the flat direction. Mousse 'spheres' this landscape first, allowing the spectral update to move appropriately in both.
Key Novelty
Muon Optimization Utilizing Shampoo’s Structural Estimation (Mousse)
- Combines spectral optimization (Muon) with second-order preconditioning (Shampoo) by performing the Newton-Schulz spectral update inside a coordinate system whitened by Kronecker-factored curvature statistics
- Eliminates the need for Adam-style second moment states found in SOAP by relying on the spectral constraint for step size regulation, reducing memory overhead while retaining geometric adaptivity
Architecture
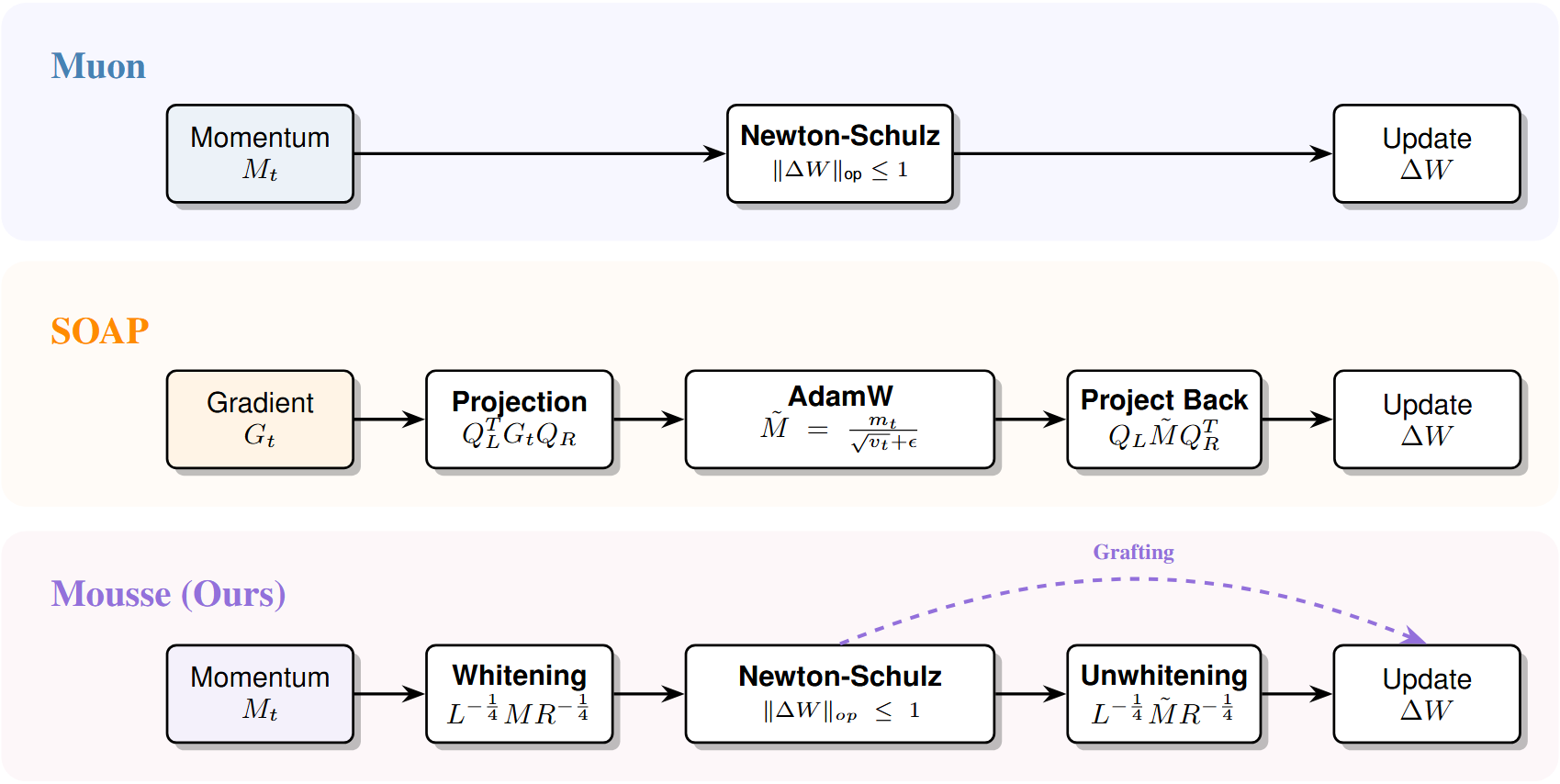
Schematic comparison of update mechanisms for Muon, SOAP, and Mousse
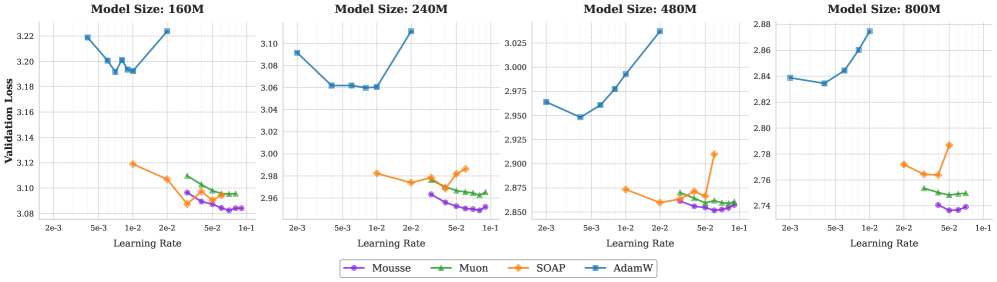
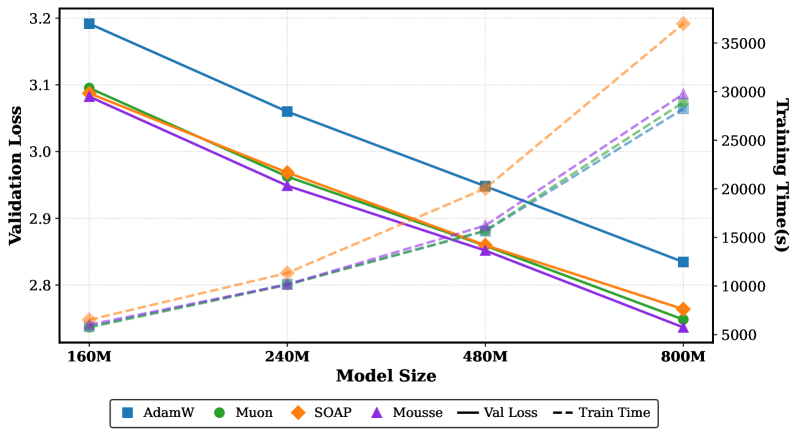
Evaluation Highlights
- Reduces training steps by ~12% to reach the same target loss compared to standard Muon on 800M parameter models
- Lowers final validation loss by 0.012 on an 800M parameter model compared to the best Muon baseline
- Incurs only ~3% wall-clock time overhead compared to Muon, significantly outperforming the throughput of SOAP
Breakthrough Assessment
8/10
Offers a theoretically grounded unification of spectral and second-order methods that yields strict Pareto improvements in efficiency (lower loss, faster convergence) with negligible computational cost.