📝 Paper Summary
Embodied AI
Spatial Reasoning
3D Scene Understanding
World2Mind is a training-free toolkit that empowers foundation models to perform complex spatial reasoning by converting egocentric video inputs into structured, allocentric 3D cognitive maps.
Core Problem
Multimodal Foundation Models (MFMs) struggle with spatial tasks like path planning and distance estimation because they rely on egocentric (first-person) observations and cannot abstract a global (allocentric) layout.
Why it matters:
- Current MFMs are trapped in a 'semantic-geometry gap,' excelling at visual recognition but failing at physical interaction tasks requiring global topology
- Training-based solutions on 3D data lead to overfitting statistical shortcuts rather than genuine spatial cognition
- Active rendering methods are computationally expensive and bottlenecked by reconstruction quality, failing to provide high-level logical abstractions
Concrete Example:
In tasks like 'Relative Direction' or 'Route Planning,' a standard model like GPT-5.2 fails to account for unobserved space or occlusions in a video walk-through, while World2Mind constructs a top-down map to correctly identify valid paths.
Key Novelty
Allocentric-Spatial Tree (AST) & Interwoven Reasoning
- Constructs an Allocentric-Spatial Tree (AST) that represents scene objects not as pixels but as a directed graph of elliptical parameters (center, axes, rotation) in a top-down view
- Implements a 'geometry-semantics interwoven reasoning chain' where the model actively cross-validates its visual impressions against the objective geometric map to resolve conflicts like illusions or occlusions
Architecture
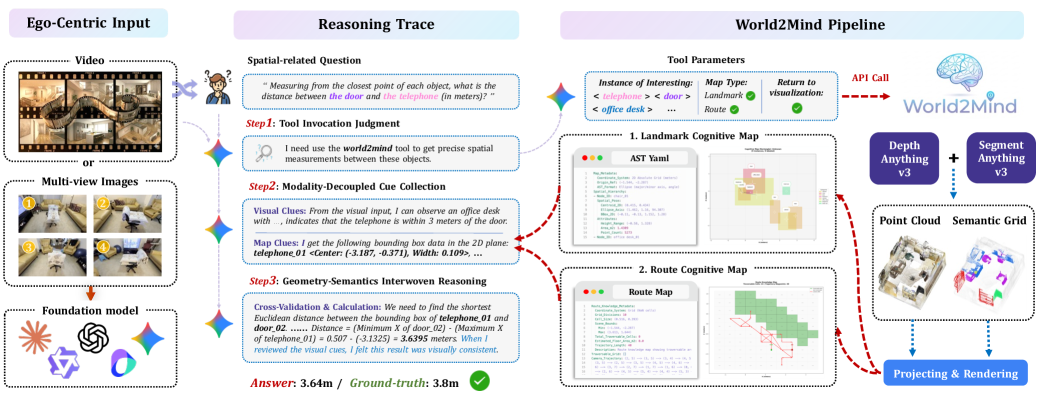
Technical overview of the World2Mind pipeline, from input video to final spatial reasoning.
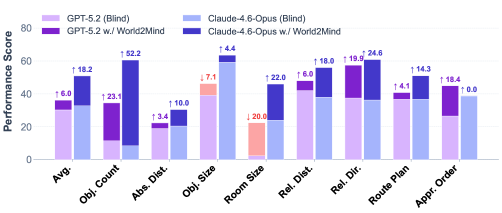
Evaluation Highlights
- +17.6% average accuracy improvement on VSI-Bench for Claude-4.6-Opus compared to the base model (38.4% to 56.0%)
- +30.6% improvement on Route Planning tasks for Claude-4.6-Opus on VSI-Bench, demonstrating the efficacy of the route cognitive map
- Text-only foundation models using only the AST text representation achieve performance approaching advanced multimodal models, proving the density of the geometric priors
Breakthrough Assessment
9/10
Offers a significant conceptual leap by enabling text-only models to perform 3D reasoning via structured abstractions (AST), decoupling spatial intelligence from raw visual perception without model training.