📝 Paper Summary
Chain of Thought Reasoning
Mechanistic Interpretability
Computational Complexity in AI
The paper formalizes 'opaque serial depth'—the maximum uninterpretable serial computation a model can perform—to quantify why Transformers need Chain of Thought for hard tasks.
Core Problem
We lack a precise, formal way to measure how much 'silent' serial reasoning a neural network can perform without externalizing its thought process.
Why it matters:
- Chain of Thought monitoring is a key AI safety mitigation, relying on the assumption that models *must* think out loud to solve hard tasks
- Without a formal measure, we cannot rigorously compare how different architectures (e.g., RNNs vs. Transformers) affect the necessity of externalized reasoning
- Standard layer counting is insufficient because it doesn't account for what constitutes a layer or how different operations (like attention vs. MLP) contribute to computational depth
Concrete Example:
A standard Transformer trying to solve a planning problem (like in an MDP) without Chain of Thought might fail because the serial depth of a single forward pass is insufficient (O(1) or O(log n)), whereas an RNN could theoretically perform deeper serial reasoning internally, bypassing the monitorable Chain of Thought.
Key Novelty
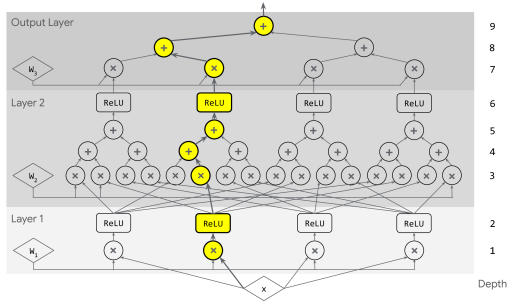
Opaque Serial Depth Metric
- Adapts 'circuit depth' from complexity theory to measure the longest path of uninterpretable serial computation in a neural network
- Treats intermediate tokens (Chain of Thought) as 'interpretable bottlenecks,' effectively resetting the serial depth count between tokens
- Provides a way to upper-bound the reasoning capacity of 'silent' forward passes for arbitrary architectures (Transformers, RNNs, Mixture-of-Experts)
Architecture
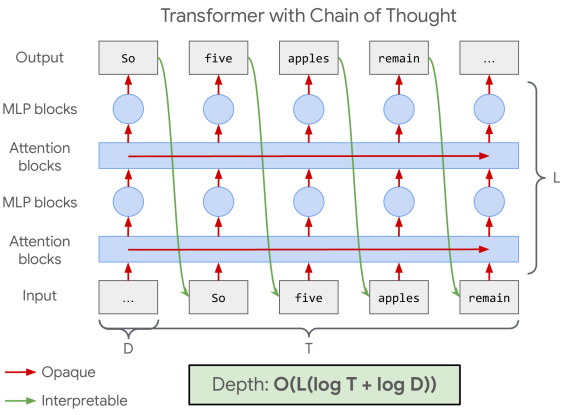
Comparison of Opaque Serial Depth across different architectures (Transformer, RNN, Continuous CoT)
Evaluation Highlights
- Calculated upper bounds for Gemma 3 models: 1B variant has opaque serial depth of 124, while 27B variant has depth of 376
- Demonstrated that Mixture-of-Experts (MoE) models likely have lower opaque serial depth than dense models due to conditional computation paths
- Established asymptotic bounds: Transformers have depth O(L(log T + log D)), while RNNs have significantly higher potential depth of O((L+T) log D)
Breakthrough Assessment
7/10
Offers a rigorous theoretical foundation for a widely held intuition (CoT necessity). While primarily theoretical, it provides concrete metrics for safety monitoring and architecture comparison.