📝 Paper Summary
Modularized RAG pipeline
Retrieval
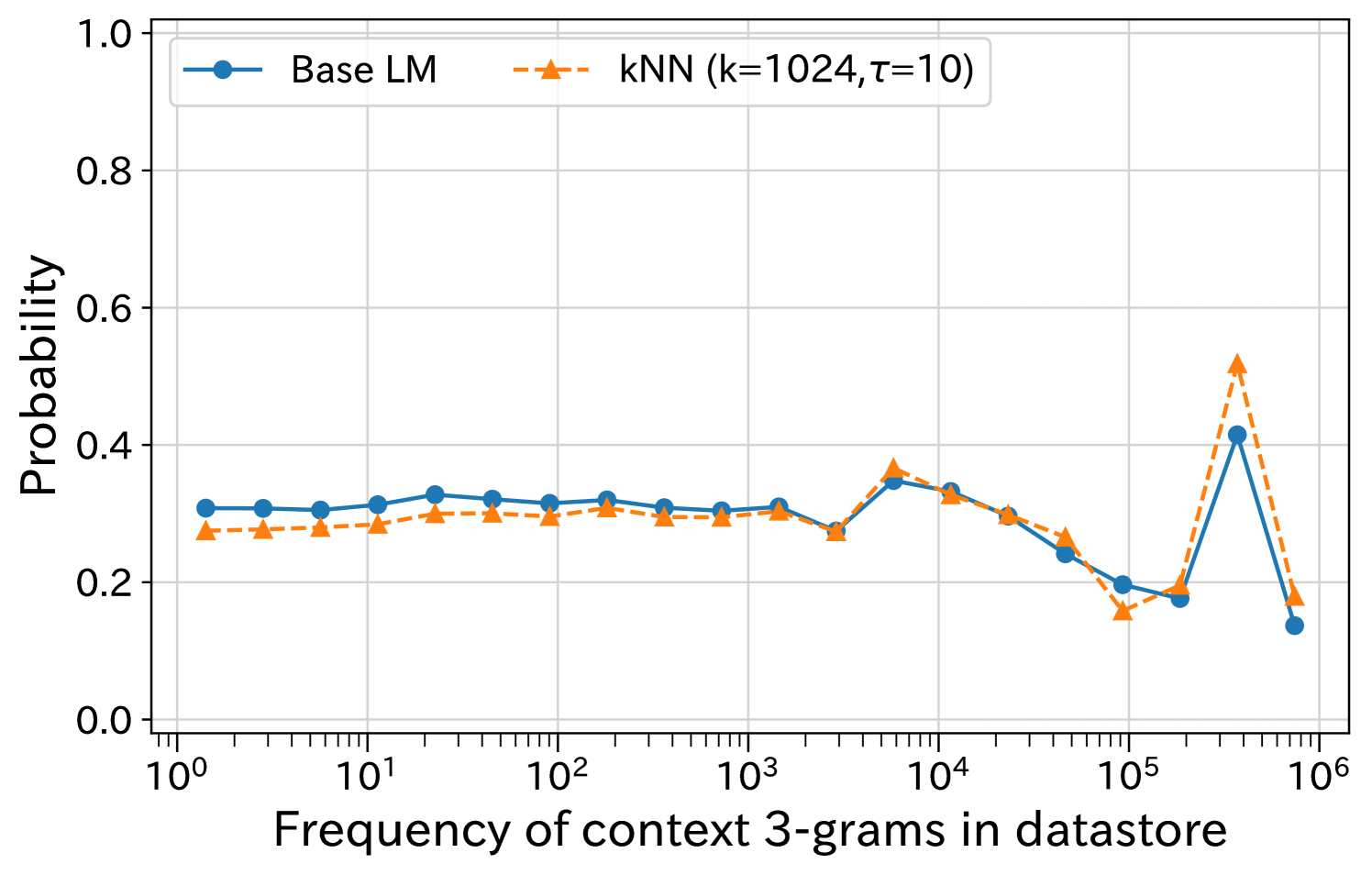
Contrary to the popular belief that kNN-LM improves long-tail prediction, detailed analysis reveals it actually worsens performance on low-frequency target tokens due to retrieval failures and quantization errors.
Core Problem
A widely held hypothesis claims retrieval-augmented models like kNN-LM succeed by improving predictions for long-tail (low-frequency) phenomena, but this has only been verified for contexts, not target tokens.
Why it matters:
- Understanding the true source of kNN-LM's success is critical for future improvements; if the long-tail hypothesis is false, optimization efforts are misdirected
- Current kNN-LM implementations may be silently degrading performance on rare vocabulary items while boosting common ones, masking the issue in aggregate metrics like perplexity
- The assumption that explicit memory fixes the long-tail problem leads researchers to overlook fundamental retrieval and representation failures for rare tokens
Concrete Example:
When predicting a low-frequency target token, kNN-LM often fails to retrieve that token in the top neighbors, assigning it zero or near-zero probability. Consequently, the interpolated probability for the rare token becomes lower than the base LM's original prediction, worsening the loss.
Key Novelty
Debunking the Long-Tail Hypothesis in kNN-LM
- Demonstrates that kNN-LM improves perplexity primarily by boosting high-frequency tokens, not low-frequency ones as previously assumed
- Identifies that low-frequency tokens suffer from 'hubness' issues where their vector space is invaded by other tokens, making retrieval difficult
- Shows that Product Quantization (PQ) introduces disproportionately high reconstruction errors for rare tokens, further degrading their retrievability
Architecture
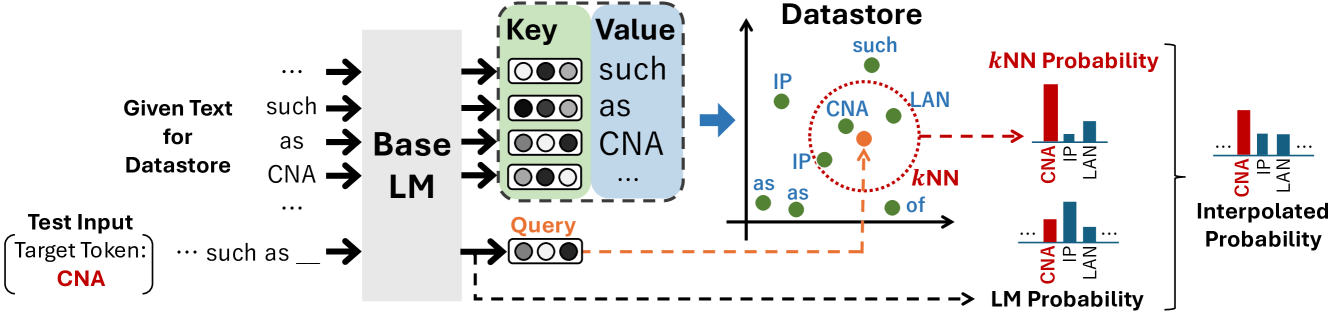
Overview of the kNN-LM inference process, illustrating how the base LM vector is used to query a datastore and interpolate probabilities.
Evaluation Highlights
- kNN-LM probability for low-frequency tokens is consistently lower than the base LM probability, while it is higher for high-frequency tokens
- Retrieval recall for the target token drops significantly as token frequency decreases; most low-frequency targets are not found in the top-1024 neighbors
- Reconstruction error from Product Quantization is significantly higher for low-frequency tokens compared to high-frequency ones
Breakthrough Assessment
7/10
A significant analytical paper that challenges a core assumption in the field. While it doesn't propose a new architecture, its negative result is crucial for redirecting future research on retrieval-augmented LMs.