📝 Paper Summary
Linear memory
Tree/graph-based memory
Agentic RAG pipeline
This approach optimizes sequential long-context reasoning by organizing text chunks into a dependency tree and processing them in breadth-first order to minimize information loss in limited memory.
Core Problem
Sequential reasoning systems like Chain-of-Agents compress context into a bounded memory, causing information loss when related evidence is processed far apart due to arbitrary document ordering.
Why it matters:
- Fixed-size memory updates act as a lossy bottleneck; if chunk A depends on chunk B but they are separated by many steps, the connection is lost.
- Existing methods rely on default document order or naive similarity ranking, which fails to capture inter-chunk statistical dependencies necessary for complex reasoning.
- Improving effective context usage is critical as nominal context windows expand but 'lost-in-the-middle' and reasoning degradation persist.
Concrete Example:
In a long mystery novel, a clue in Chapter 1 might only make sense when combined with a reveal in Chapter 20. If processed sequentially by default, the memory might discard the Chapter 1 clue to save space before reaching Chapter 20. Chow-Liu ordering identifies they are related and schedules them to be processed closer together.
Key Novelty
Dependency-Aware Chow-Liu Tree Ordering
- Models text chunks as random variables and approximates their global dependency structure using a Chow-Liu tree (Maximum Spanning Tree based on similarity).
- Replaces default sequential processing with a Breadth-First Traversal of this tree, rooted at the chunk most similar to the query.
- Ensures that statistically dependent or complementary chunks are processed consecutively, reducing the risk that the shared memory 'forgets' context needed for subsequent reasoning.
Architecture
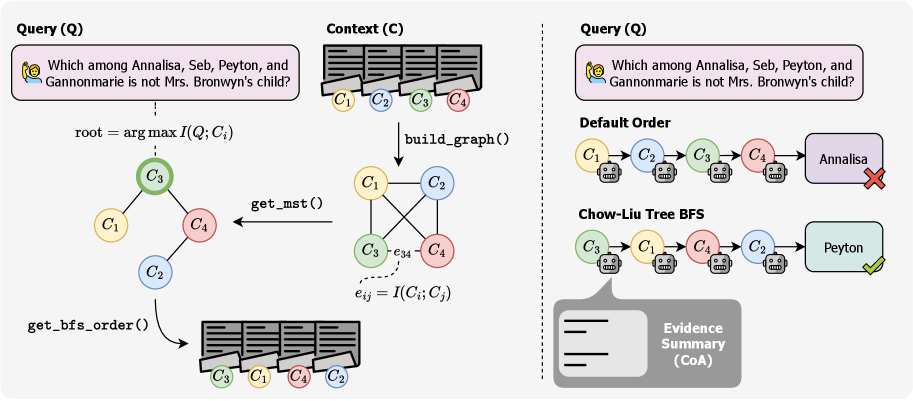
Overview of the methodology: converting chunks to a weighted graph, computing the Maximum Spanning Tree, and determining the processing order via BFS traversal rooted at the query.
Evaluation Highlights
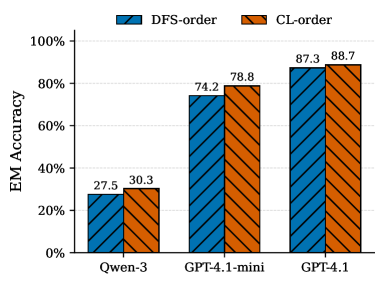
- Achieves 10.68% relative gain in Exact Match accuracy over default document ordering on long-context benchmarks.
- Outperforms semantic score-based ordering (ranking by query similarity) by 6.89% relative gain in Exact Match.
- Consistent improvements in Answer Relevance across GPT-4.1, GPT-4.1-mini, and Qwen-3-14B on NarrativeQA and HELMET datasets.
Breakthrough Assessment
7/10
A theoretically grounded improvement to the heuristic 'ordering' problem in sequential agents. While specific to CoA-style architectures, it applies rigorous probabilistic structure learning to memory management.