📝 Paper Summary
Agentic Recommendation
Tool-Augmented Reasoning
RecThinker is an investigator agent that actively assesses information gaps in user profiles and item data, autonomously calling specialized tools to bridge these gaps before making recommendation decisions.
Core Problem
Existing recommendation agents operate passively with static workflows or constrained information, failing to identify when they lack sufficient evidence for accurate reasoning.
Why it matters:
- Passive agents rely on uncertain or opportunistic tool use rather than driven by information deficiency, leading to ineffective actions
- Current frameworks typically use generic search tools not tailored for recommendation, resulting in incomplete or one-sided evidence
- Fragmented user profiles and sparse item metadata lead to suboptimal recommendations when agents cannot proactively seek missing context
Concrete Example:
When a user has a sparse history, a standard agent might hallucinate preferences or make a generic guess. RecThinker detects this 'information gap,' actively calls a 'Similar Users Search' tool to infer preferences from collaborative data, and then ranks items.
Key Novelty
Agent-as-Investigator with Analyze-Plan-Act Workflow
- Adopts an 'Analyze-Plan-Act' paradigm where the agent explicitly assesses the gap between available knowledge (user/item info) and what is needed for ranking
- Uses a suite of recommendation-specific tools (e.g., collaborative filtering signals via similar user search, item relation graphs) rather than just generic web search
- Optimizes policy via a two-stage process: Self-Augmented SFT on high-quality filtered trajectories followed by Reinforcement Learning (GRPO) for tool efficiency
Architecture
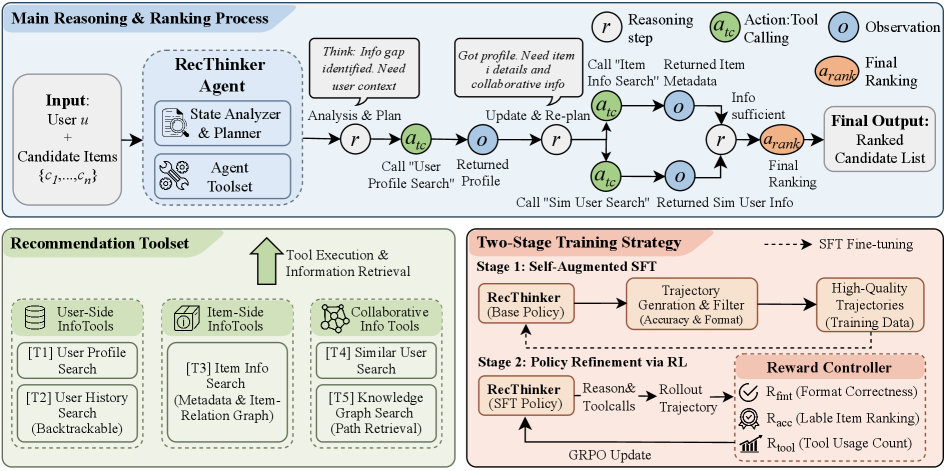
The overall architecture and Analyze-Plan-Act workflow of RecThinker.
Breakthrough Assessment
8/10
Moves beyond the standard 'Agent-as-Assistant' model to a proactive 'Investigator' model that self-diagnoses information needs. The integration of specialized recommendation tools with an explicit 'Analyze-Plan-Act' loop is a significant methodological advance.