📝 Paper Summary
Non-prehensile manipulation
Robotic manipulation in clutter
Dynamics representation learning
DAPL enables robots to manipulate objects in dense clutter by learning a dynamics-aware world model that predicts how contacts propagate momentum, using this to condition a reinforcement learning policy.
Core Problem
Manipulating objects in cluttered scenes requires 'extrinsic dexterity'—using the environment to push or slide objects—but current methods fail because they cannot predict complex, coupled contact dynamics among multiple objects.
Why it matters:
- Real-world environments (shelves, fridges) are tightly packed, making grasping often impossible without moving other objects first
- Existing geometry-based policies treat obstacles as static or purely geometric constraints, failing to exploit beneficial contacts (e.g., using a heavy object as a backstop)
- Model-based planning does not scale to the unpredictable contact chains found in dense clutter
Concrete Example:
A robot needs to flip a target object in a packed box. A geometry-only policy avoids touching neighbors, failing the task. DAPL intentionally pushes the target against a stable heavy neighbor to flip it, leveraging the neighbor's inertia.
Key Novelty
Dynamics-Aware Policy Learning (DAPL)
- Decouples dynamics learning from policy learning: trains a world model to predict future object velocities and positions under robot interaction, explicitly modeling contact-induced motion
- Uses a curriculum that alternates between RL policy exploration and world model refinement, where the policy generates diverse interaction data to improve the dynamics model
- Conditions the RL policy on the learned latent dynamics embedding, giving it a 'physical intuition' about mass and friction without manual parameter tuning
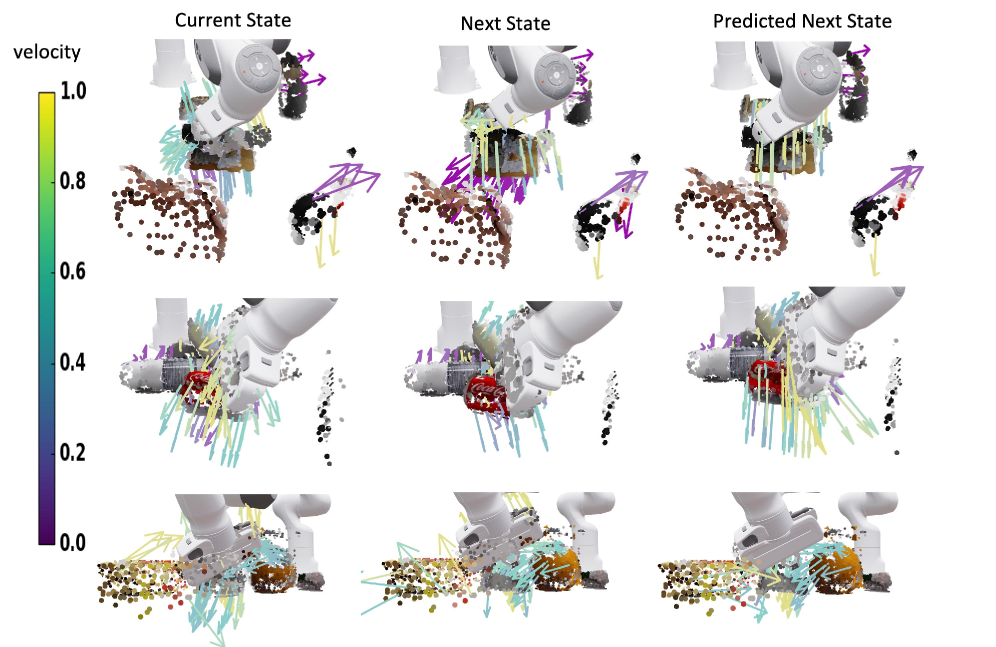
Architecture

The DAPL framework pipeline: World Model learning (top) and Policy Learning (bottom).
Evaluation Highlights
- +22.3% success rate improvement over state-of-the-art representation baselines (CORN) in dense simulated clutter (44.56% vs 22.22%)
- Achieves ~50% success rate in zero-shot real-world deployment across 10 diverse cluttered scenes, comparable to human teleoperation
- Reduces unintended disturbance to surrounding objects by ~27% compared to CORN (12.65cm vs 17.43cm mean offset)
Breakthrough Assessment
8/10
Significant advance in non-prehensile manipulation by effectively learning contact dynamics rather than just geometry. Strong sim-to-real transfer and large performance gains in dense clutter.