📝 Paper Summary
Class-Incremental Learning (CIL)
Memory internalization
Parameter-Efficient Fine-Tuning (PEFT)
LCA combines incremental merging of parameter-efficient modules with a novel alignment loss that regularizes classifiers using local Gaussian sampling to mitigate mismatch between updated backbones and frozen heads.
Core Problem
Merging task-specific backbones in continual learning creates a mismatch between the evolved feature extractor and frozen past classifiers, causing performance drops.
Why it matters:
- Updating the backbone for new tasks inevitably shifts feature distributions, invalidating previous classifiers that cannot be retrained without access to old data.
- Existing methods that freeze the backbone or use prototypes often fail to capture task-specific nuances or struggle as distributions diverge over long task sequences.
- Naive sequential fine-tuning leads to catastrophic forgetting, while retraining everything is computationally expensive and memory-intensive.
Concrete Example:
After training on Task A and then Task B, merging their backbones shifts the feature space. A classifier trained originally for Task A now receives shifted embeddings from the merged backbone, leading to misclassification because it expects the original Task A features.
Key Novelty
Local Classifier Alignment (LCA) with Incremental PEFT Merging
- Treats each class as a Gaussian distribution in feature space and generates synthetic samples to retrain all classifiers (new and old) without storing original data.
- Introduces a regularization term that penalizes sensitivity to small input changes around class prototypes, ensuring classifiers remain robust to feature shifts caused by backbone updates.
- Incrementally merges Parameter-Efficient Fine-Tuning (PEFT) modules by selecting parameters with large deviations, maintaining a unified backbone that integrates knowledge from all tasks.
Architecture
The process of incremental backbone consolidation and classifier alignment.
Evaluation Highlights
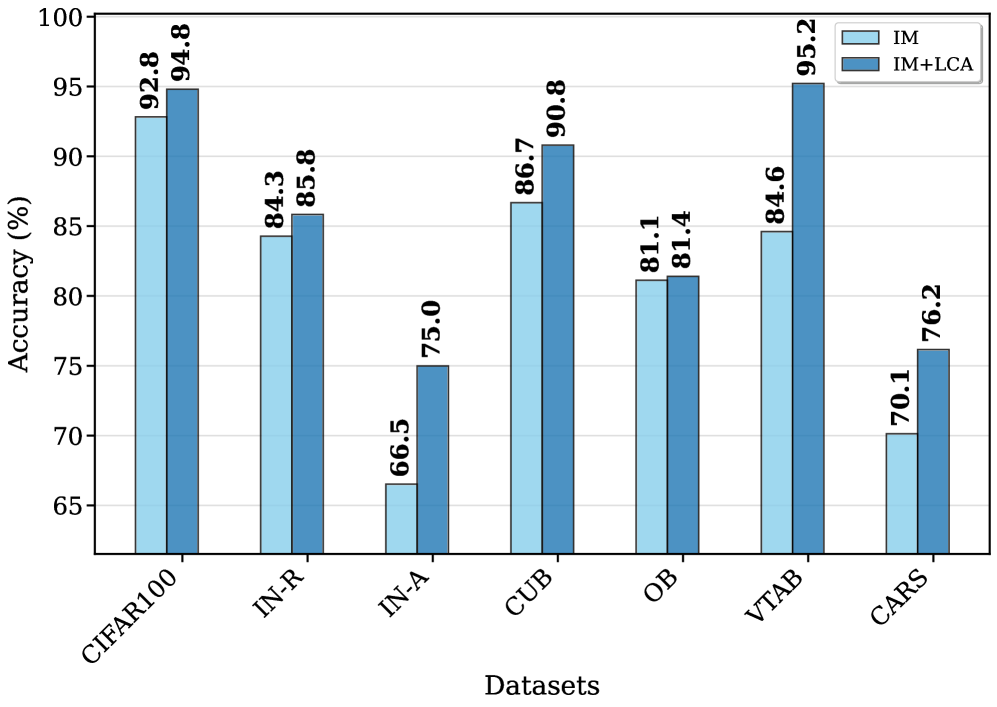
- Achieves leading performance on 7 benchmark datasets, effectively handling long task sequences.
- Outperforms state-of-the-art methods like EASE and recent prompting baselines on standard Class-Incremental Learning benchmarks.
- Demonstrates high robustness by minimizing the mismatch between the merged backbone and classifiers via the proposed alignment loss.
Breakthrough Assessment
8/10
Strong theoretical grounding for the alignment loss coupled with a practical, memory-efficient merging strategy. Effectively addresses the backbone-classifier mismatch problem in CIL.