📝 Paper Summary
Continual Learning
Catastrophic Forgetting Mitigation
MSSR mitigates catastrophic forgetting in continual LLM fine-tuning by modeling sample-level retention dynamics and adaptively scheduling replay based on the Ebbinghaus forgetting curve.
Core Problem
Continual fine-tuning of LLMs causes catastrophic forgetting, and existing replay strategies are either heuristic (fixed intervals), reactive (wait for loss spikes), or computationally expensive (frequent evaluation).
Why it matters:
- LLMs deployed in dynamic environments must acquire new knowledge without degrading previously learned skills (e.g., in healthcare or law).
- Current methods inadequately model the temporal heterogeneity of forgetting, often assuming uniform replay needs across time.
- Scalability is limited because monitoring overhead for accuracy-based replay becomes prohibitive in long training runs.
Concrete Example:
In a sequence like Alpaca → GSM8K → Math, a model trained on Math might forget basic instruction following (Alpaca). Fixed replay wastes compute on stable samples, while accuracy-based replay only triggers after performance has already dropped significantly.
Key Novelty
Memory-Inspired Sampler and Scheduler Replay (MSSR)
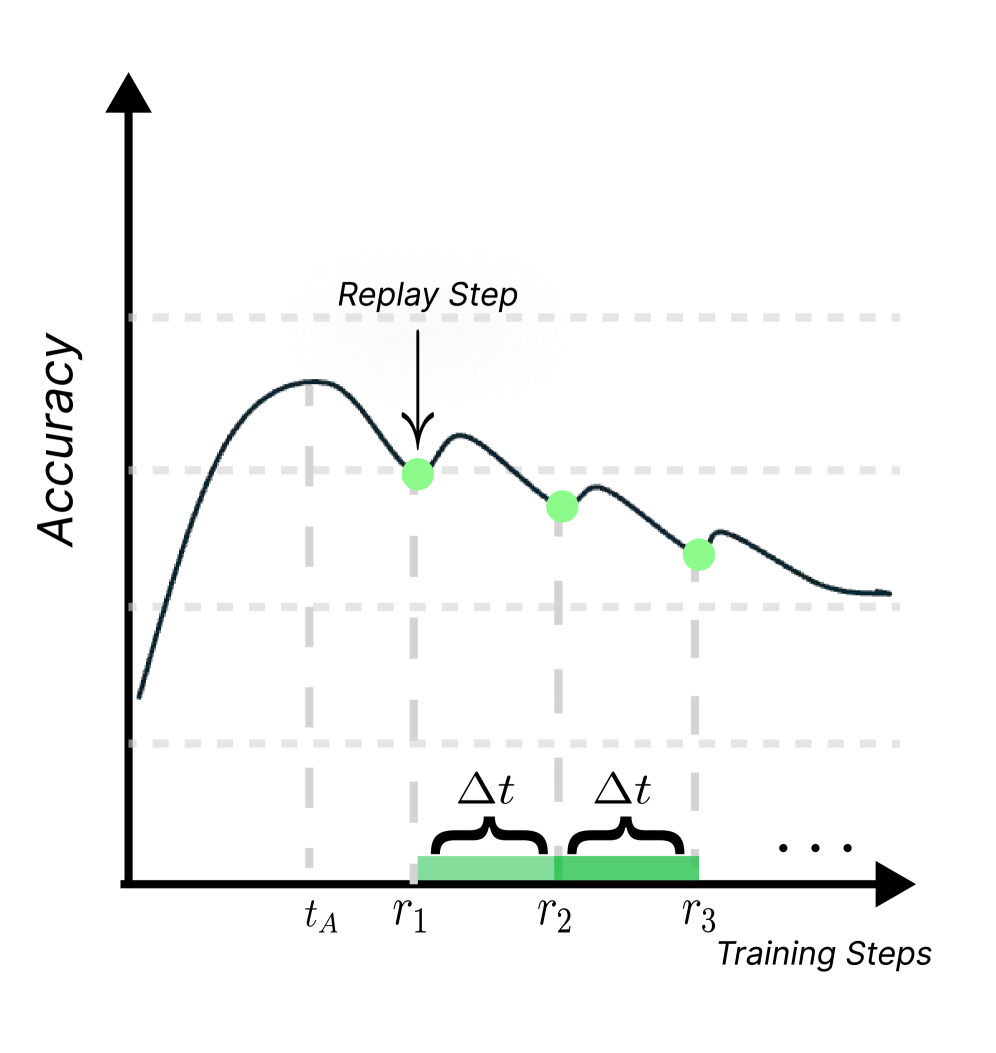
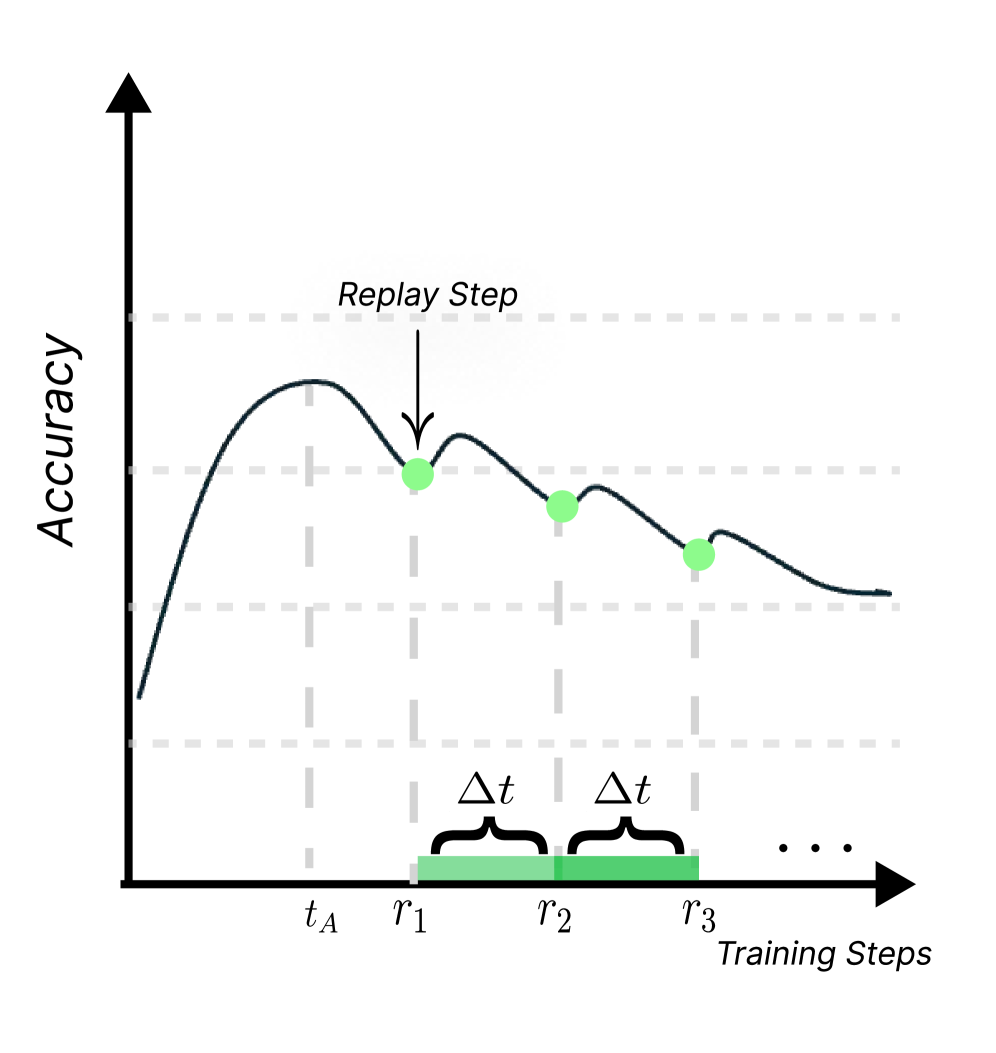
- Models each data sample's 'memory strength' as a decaying value that increases with replay and decays over time, inspired by the Ebbinghaus forgetting curve.
- Replay intervals expand over time (spacing effect): replay is frequent initially when forgetting is rapid, and becomes sparser as memory stabilizes.
- Prioritizes replay for samples with lower memory strength (higher forgetting risk) rather than random selection.
Architecture
The MSSR framework workflow, illustrating the closed-loop interaction between memory tracking, replay scheduling, and fine-tuning.
Evaluation Highlights
- Achieves strongest consistent performance across 3 backbone models (Qwen2.5, Gemma2, Llama-3.1) on sequential reasoning tasks.
- Outperforms fixed and accuracy-based replay baselines on the 11-task long-sequence benchmark while reducing computational overhead.
- Effectively mitigates early-task forgetting in long sequences compared to reactive baselines.
Breakthrough Assessment
7/10
Offers a principled, theoretically grounded alternative to heuristic replay. While the core concept (Ebbinghaus) is established in psychology, applying it to sample-level scheduling for LLM continual learning is a solid methodological contribution.