📝 Paper Summary
Medical Multi-Agent Systems (MAS)
Multimodal Benchmarking
Clinical Reasoning Verification
MedMASLab is a unified platform that standardizes medical multi-agent system execution and introduces a multimodal semantic judge to replace brittle string-matching metrics in clinical benchmarking.
Core Problem
Current medical Multi-Agent Systems (MAS) suffer from architectural fragmentation, incompatible data pipelines, and brittle rule-based evaluation metrics that punish valid clinical reasoning.
Why it matters:
- Fragmentation prevents fair comparison between different MAS architectures (e.g., debate vs. hierarchical), hindering progress in autonomous clinical support
- Traditional metrics like Exact Match fail to capture clinical nuance, penalizing correct diagnoses simply for varying output formats
- The lack of standardized auditing makes it impossible to trace error propagation in complex multi-doctor simulations, risking patient safety
Concrete Example:
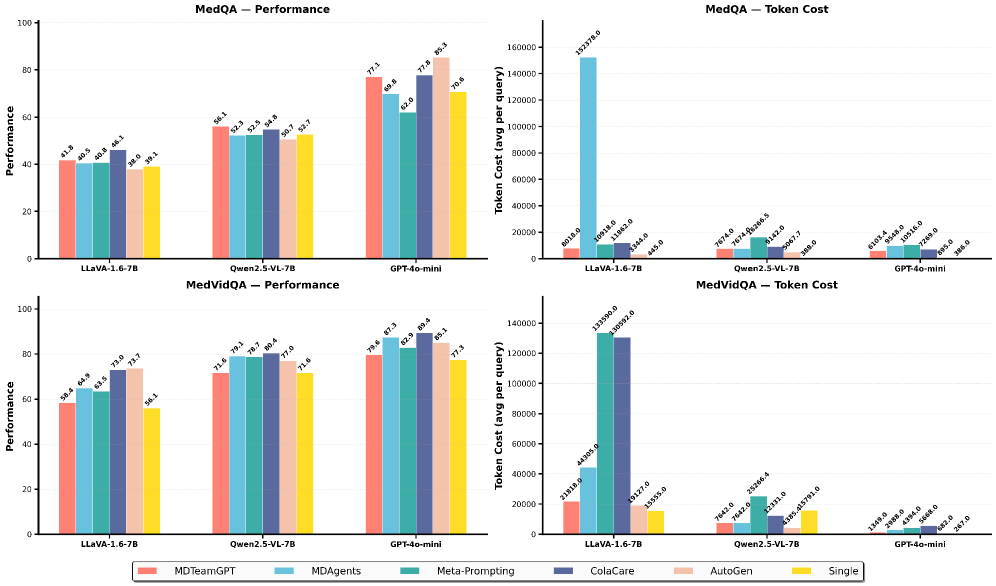
On PubMedQA, the MDTeamGPT method achieves 79.40% accuracy when evaluated by a semantic judge but collapses to 0.40% under Multi-Regex matching because verbose clinical reasoning confuses standard extraction scripts.
Key Novelty
MedMASLab Orchestration & Semantic Verification
- Decouples agent logic from model inference via a standardized communication protocol, allowing 11 different MAS architectures to run on identical data and compute resources
- Replaces rigid text matching with a 'Semantic Judge' (VLM-SJ) that uses a powerful Vision-Language Model to verify if an agent's verbose diagnosis is semantically equivalent to the ground truth
Architecture
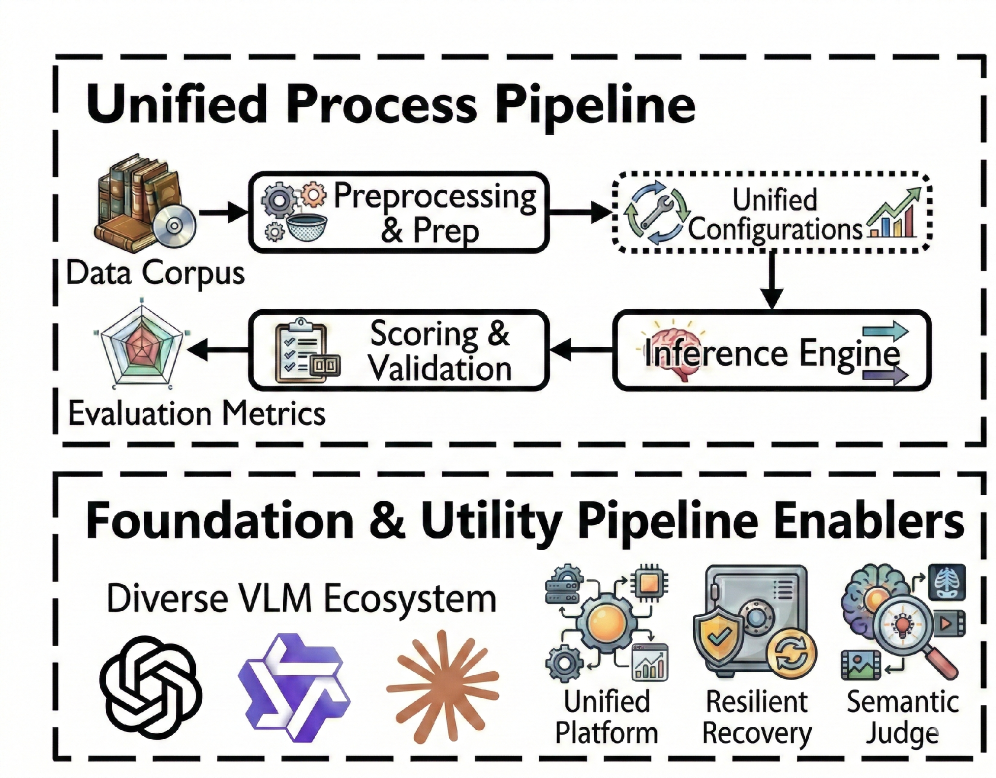
The MedMASLab orchestration framework structure, decoupling the agent layer from the serving layer.
Evaluation Highlights
- VLM-SJ (Semantic Judge) rescues valid reasoning: MDTeamGPT performance on PubMedQA jumps from 0.40% (Rule-MR) to 79.40% (VLM-SJ)
- Identifies 'Specialization Penalty': General MAS methods degrade significantly when moved to specialized medical sub-domains, with no single method dominating across all 11 benchmarks
- Reveals cost-performance trade-offs: Increasing agent count in MDTeamGPT improves MedQA accuracy up to 8 agents, after which performance degrades while costs rise
Breakthrough Assessment
9/10
Establishes the first unified benchmark and execution environment for medical MAS, exposing critical flaws in previous evaluation methods and offering a robust, standardized solution.