📝 Paper Summary
Efficient LLM Scaling
Mixture of Experts (MoE) Architecture
MoLAE compresses standard Mixture of Experts models by factorizing expert weight matrices into a shared low-dimensional latent projection followed by expert-specific transformations, reducing parameters without sacrificing performance.
Core Problem
Standard Mixture of Experts (MoE) architectures suffer from high memory consumption and communication bottlenecks due to parameter redundancy in Feed-Forward Network (FFN) layers.
Why it matters:
- As models scale to hundreds of experts, the memory footprint limits deployment in resource-constrained environments
- All-to-all data transfers during distributed training create significant communication overhead
- Empirical analysis shows current MoE FFN layers have high redundancy (e.g., Qwen1.5-MoE-A2.7B), suggesting wasted computational resources
Concrete Example:
In DeepSeek-V3, the hidden dimension (n=7168) is much larger than the intermediate dimension (m=2048). A standard MoE stores independent m×n matrices for every expert, whereas MoLAE shares the large projection part, storing only small m×m matrices per expert.
Key Novelty
Mixture of Latent Experts (MoLAE)
- Replaces independent expert matrices with a two-step process: a shared projection into a compressed latent space, followed by lightweight expert-specific processing
- Mathematically factorizes high-dimensional weight matrices (W) into a product of expert-specific low-rank matrices (A) and a shared base matrix (B)
- Introduces a grouping mechanism where subsets of experts share the same latent mapping, allowing a tunable trade-off between efficiency and specialization
Architecture
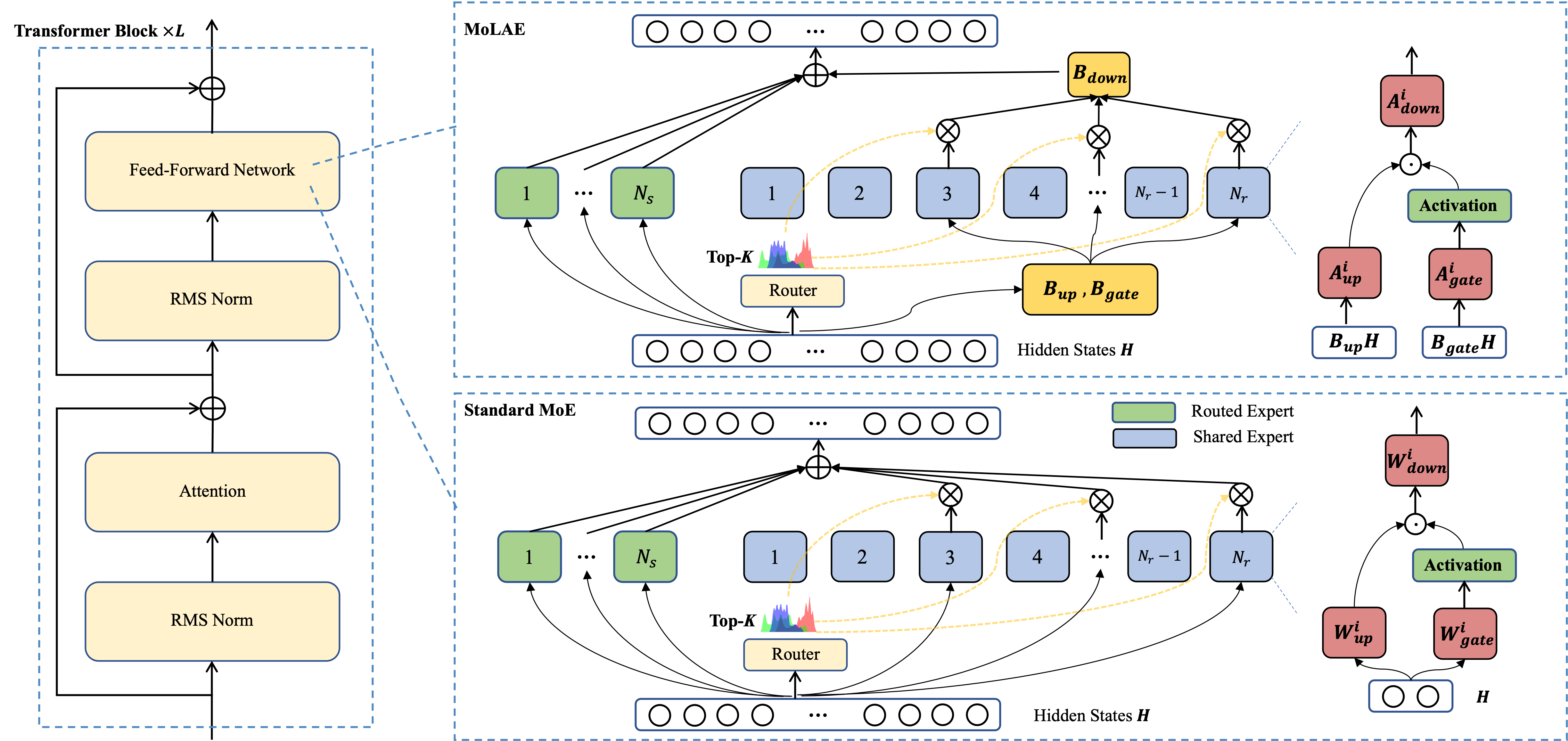
Visual comparison between standard Mixture of Experts (MoE) and Mixture of Latent Experts (MoLAE) architectures.
Evaluation Highlights
- Retaining only 80% of the rank in FFN operators (r=0.8) for Qwen1.5-MoE-A2.7B results in no significant performance degradation on MMLU or Wikitext-2
- Reduced-rank Qwen1.5 model actually improved GSM8K accuracy by +1.1 percentage points compared to the full-rank baseline
- MoLAE significantly reduces parameter count compared to standard MoE when the hidden dimension (n) is much larger than the intermediate dimension (m), common in modern LLMs like DeepSeek-V3
Breakthrough Assessment
7/10
Strong theoretical grounding (SVD-based factorization) and clear efficiency gains. While primarily an architectural optimization rather than a new capability, it addresses critical scaling bottlenecks for MoEs.