📊 Experiments & Results
Evaluation Setup
Analysis of Input-Output Jacobian norms at initialization and after pretraining
Benchmarks:
- NaturalQuestions (NQ) (Multi-document QA (used for pre-trained context analysis))
Metrics:
- Jacobian Norm (Influence Density)
- Spearman Rank Correlation
- Wasserstein Distance
- Statistical methodology: Spearman rank correlation and Wasserstein distance to compare theoretical vs. empirical distributions
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Validation of the theoretical model against untrained networks demonstrates near-perfect fit and independence from RoPE. | ||||
| Qwen2-0.5B (Untrained) | Spearman Correlation | 1.0 | 0.99 | -0.01 |
| Qwen2-0.5B (Untrained) | Wasserstein Distance | 0.0 | 0.02 | +0.02 |
| Qwen2-0.5B (Untrained) | Spearman Correlation | 1.0 | 0.99 | -0.01 |
| NaturalQuestions | Peak-to-Trough Ratio (Log Scale) | 100 | 1000 | +900 |
Experiment Figures
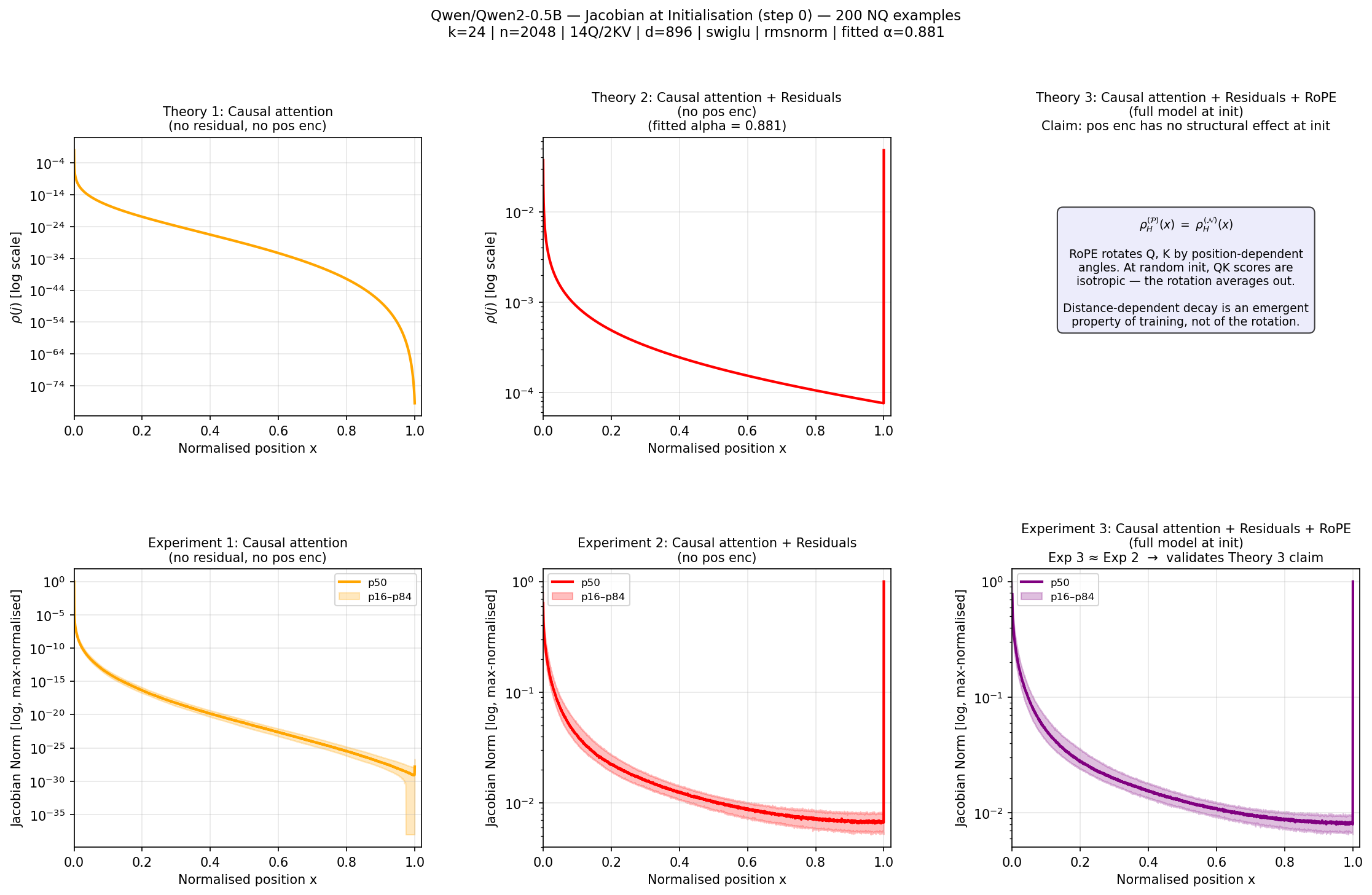
Log-scale plot comparing the Theoretical Continuous Prediction vs. Empirical Qwen2 Jacobian (Step 0) vs. Qwen2 No-RoPE Jacobian.
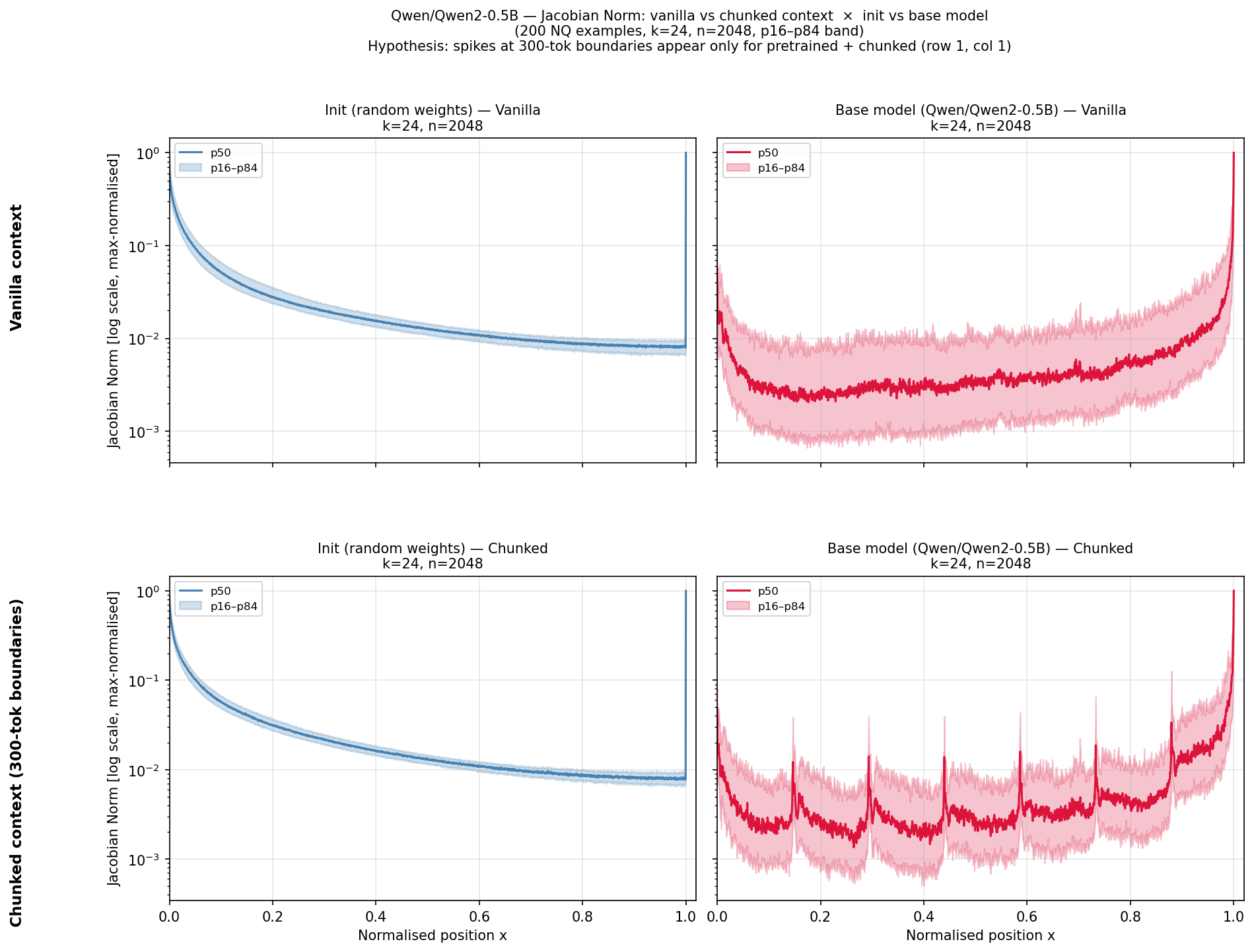
Jacobian norms for Initialized vs. Pretrained models on NaturalQuestions, including a 'chunked' condition with no separators.
Main Takeaways
- The U-shape is an inherent geometric property of causal decoders with residuals, present at Step 0.
- RoPE is mathematically irrelevant to the attention distribution at initialization due to rotational symmetry of isotropic Gaussians.
- Standard pretraining does not overcome the topological valley; it learns localized spikes (content detection) but the macroscopic dead zone persists.
- The 'middle' is a structural dead zone where gradient influence is factorially suppressed relative to the primacy and recency extremes.