📝 Paper Summary
Robotic Control
Vision-Language-Action (VLA) Models
AR-VLA decouples high-frequency motor control from low-frequency perception using a standalone autoregressive action expert that maintains continuous kinematic history while asynchronously conditioning on refreshable visual contexts.
Core Problem
Current VLA models are structurally reactive, resetting their context window at every step ('Markovian amnesia'), which prevents them from understanding trajectory momentum and handling the frequency mismatch between fast control and slow perception.
Why it matters:
- Resetting context at every step degrades fluid control into a series of disjointed, snapshot-conditioned responses (jitter)
- Standard VLAs cannot naturally handle the latency between when an image is captured and when an action is executed
- Manipulation requires 'temporal awareness' (momentum/acceleration) which is lost when treating control as isolated static chunks
Concrete Example:
In standard VLAs, at every perception step, the model acts as if 'waking up' for the first time, re-encoding the context and generating a chunk without knowing its own past velocity. This leads to temporal inconsistency compared to AR-VLA, which knows 'how' the end-effector is accelerating from past tokens.
Key Novelty
True Autoregressive Action Expert with Hybrid Memory
- Treats action generation as a continuous causal sequence maintained in a rolling history buffer, separate from the high-latency visual perception
- Uses a Hybrid Key-Value (HKV) Cache where proprioception is a FIFO stream (dynamic) and vision is a single-slot buffer (refreshable)
- Aligns these asynchronous streams using Dynamic Temporal Re-anchoring (DTR), which mathematically encodes the 'staleness' of visual frames relative to the current action step
Architecture
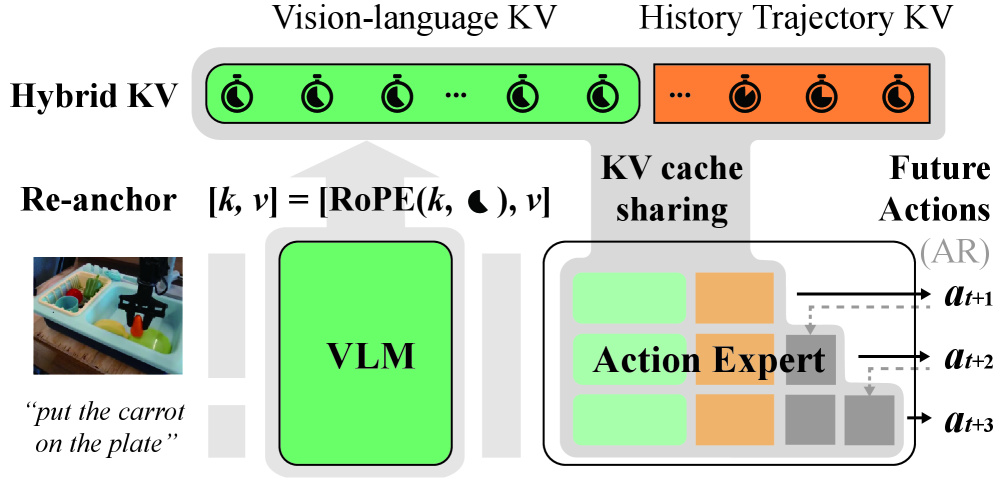
The Unified Decoder with Hybrid Key-Value Cache and Dynamic Temporal Re-anchoring (DTR).
Breakthrough Assessment
8/10
Proposes a fundamental architectural shift for VLAs—moving from reactive chunking to true autoregressive streaming with explicit handling of sensor latency/staleness.