📊 Experiments & Results
Evaluation Setup
Analysis of gradient norms and training dynamics on language modeling tasks
Benchmarks:
- The Pile subset (Language Modeling (Gradient Rank Estimation))
- Synthetic Language (Controlled Pattern Learning) [New]
Metrics:
- Gradient Norm Suppression (%)
- Effective Rank of Logit Gradients
- Training Efficiency (Convergence Speed)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| The Pile (Pythia models) | Gradient Norm Suppression | 100 | 1-5 | -95 to -99 |
| 2B Parameter LM Pretraining | Training Efficiency Factor | 1.0 | 0.0625 | Reduced by ~16x |
Experiment Figures
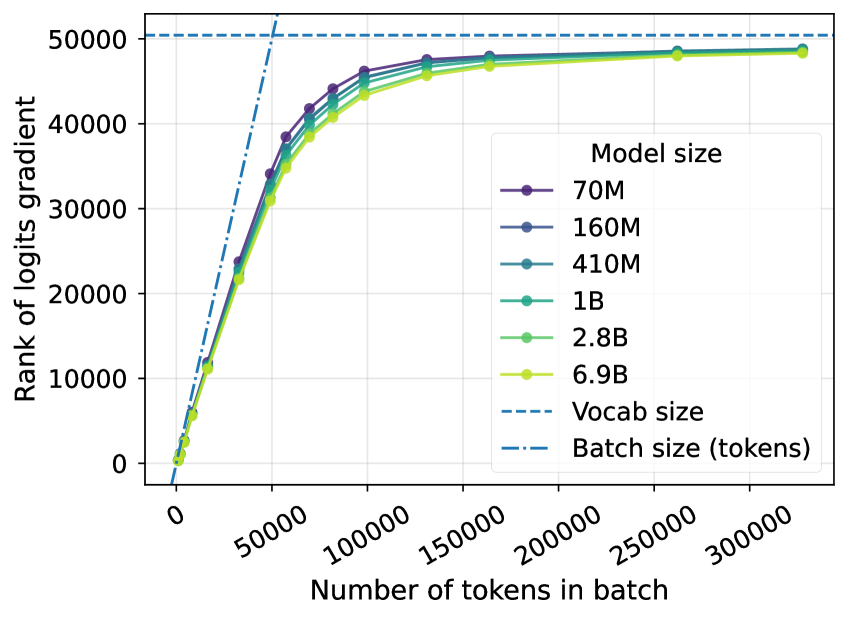
Empirical ranks of logit gradients for Pythia models measured on The Pile
Main Takeaways
- The LM head destroys 95-99% of the gradient norm during backpropagation, effectively adding massive noise to the update signal.
- The 'softmax bottleneck' is primarily an optimization issue: even when a model can theoretically represent the solution, the low-rank gradient makes learning trivial patterns impossible.
- Increasing the hidden dimension D improves convergence speed significantly, up to 4,096 dimensions, validating the bottleneck theory.
- Replacing the softmax with higher-expressivity alternatives (like Mixture of Softmaxes) theoretically fails to solve the optimization bottleneck because the Jacobian remains rank-limited.