📝 Paper Summary
Parameter-Efficient Fine-Tuning (PEFT)
Model Merging
Transfer Learning
Mashup Learning accelerates finetuning by identifying relevant historical checkpoints via loss on the target task, merging them, and using the result as a superior initialization compared to the base model.
Core Problem
Finetuning creates thousands of specialized checkpoints that are typically discarded after use, wasting the computational effort and learned capabilities embedded in their weights.
Why it matters:
- Training from scratch (base model initialization) for every new task is computationally expensive and redundant
- Large collections of open-source checkpoints (e.g., Hugging Face Hub) contain valuable transfer learning signals that are currently unexploited
- Achieving optimal performance on small datasets is difficult due to limited training examples, where better initialization could prevent overfitting
Concrete Example:
When finetuning a model for a new science reasoning task (e.g., ARC-Easy), standard approaches start from the generic base model. Mashup Learning instead detects that existing biology and physics checkpoints yield low loss on the new data, merges them, and starts training from this 'knowledgeable' state, reaching high accuracy much faster.
Key Novelty
Mashup Learning (recycling checkpoints for initialization)
- Treats historical checkpoints as a repository of recyclable skills rather than isolated artifacts
- Selects 'donor' checkpoints by measuring which ones best predict a small sample of the new task's data (lowest loss)
- Initializes the new training run with a merge (average) of these donors, effectively transferring prior knowledge to jump-start adaptation
Architecture
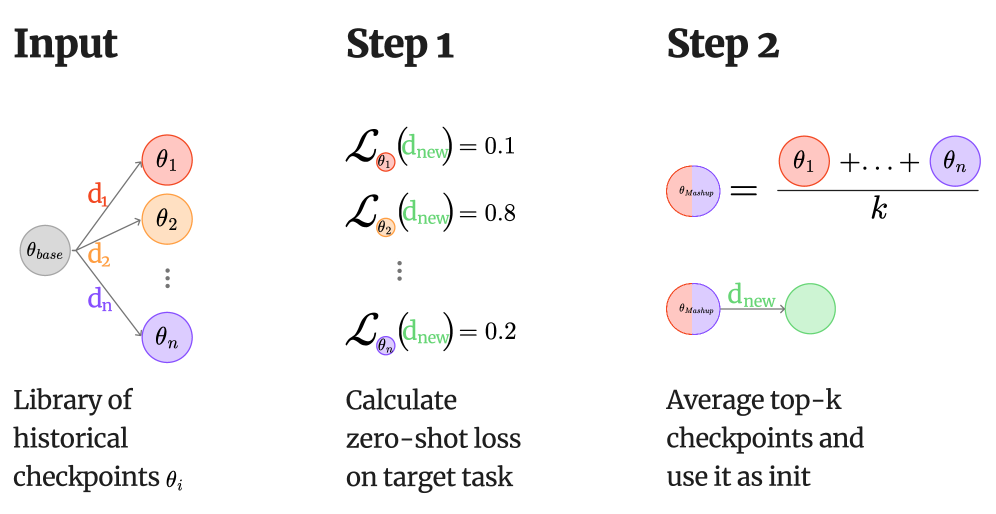
Schematic of the Mashup Learning workflow
Evaluation Highlights
- +5.1 percentage points average accuracy improvement on Mistral-7B-Instruct-v0.2 compared to training from scratch, using the Lots-of-LoRAs collection
- Accelerates convergence by matching from-scratch accuracy in 41–46% fewer training steps across Gemma models
- Reduces total wall-clock time by up to 37% (including selection and merging overhead) while improving final accuracy
Breakthrough Assessment
7/10
Simple, practical, and effective method that turns the 'waste' of past experiments into a resource. Strong empirical results on convergence speed and accuracy, though the core mechanic (averaging) is technically straightforward.