📝 Paper Summary
Agentic Reinforcement Learning
Personalized Agents
Online Learning
OpenClaw-RL enables agents to improve continuously by converting live next-state signals (like user replies or error traces) into scalar process rewards and token-level directive supervision.
Core Problem
Agents discard valuable 'next-state signals' (user corrections, tool errors) by treating them merely as context for the next turn rather than as immediate training signals.
Why it matters:
- Current systems rely on batch data collection or sparse terminal rewards, ignoring the dense, free feedback present in every interaction
- Scalar rewards in RLVR (Reinforcement Learning with Verifiable Rewards) capture *that* an action was wrong but lose the directive information regarding *how* to fix it
- Personal agents fail to adapt to user preferences in real-time because existing RL infrastructure cannot handle asynchronous live learning streams
Concrete Example:
If a user says 'you should have checked the file first', standard RL might just penalize the previous action (scalar reward). OpenClaw-RL extracts the hint 'check file first', re-runs the model with this hint to generate a better distribution, and distills that token-level correction back into the policy.
Key Novelty
Asynchronous Dual-Signal Recovery
- Decouples serving, environment, judging, and training into four independent asynchronous loops, allowing continuous updates without blocking live user interactions
- Recovers two types of signals from the same interaction: evaluative signals (good/bad) via Binary RL and directive signals (how to fix) via Hindsight-Guided On-Policy Distillation (OPD)
Architecture
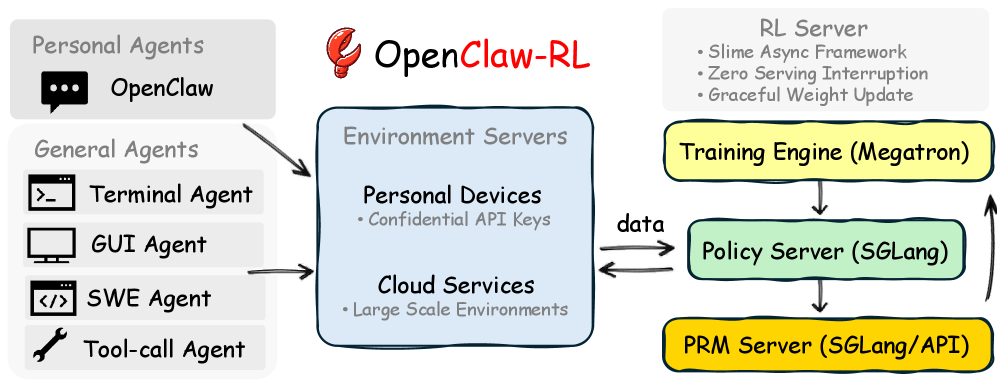
The fully decoupled asynchronous architecture of OpenClaw-RL.
Breakthrough Assessment
8/10
Proposes a significant architectural shift for online agent learning by unifying personal and general agent training in a non-blocking loop. The combination of scalar PRMs and textual distillation addresses a major efficiency gap in current RLHF.