📝 Paper Summary
Computer-Use Agents (CUA)
Reward Modeling
Video Understanding
ExeVRM is a model-agnostic evaluator that judges computer-use agent success directly from execution videos, utilizing spatiotemporal pruning and synthetically augmented data to outperform proprietary models like GPT-5.2.
Core Problem
Evaluating Computer-Use Agents (CUAs) is difficult because existing benchmarks rely on brittle, unscalable hand-crafted scripts, while outcome-based checks miss intermediate errors.
Why it matters:
- Manual scripting for evaluation limits the scalability and transferability of agents to new environments
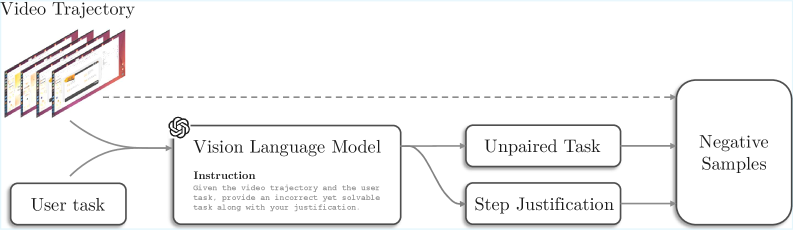
- Public datasets lack negative supervision (failure cases), making it hard to train discriminative reward models
- High-resolution execution videos are computationally expensive to process due to massive redundancy in static UI elements
Concrete Example:
A trajectory might technically reach a final state but fail due to a subtle cue like a transient error dialog or incorrect cursor focus. A script-based evaluator might crash if the UI layout changes slightly, whereas a video-based model should robustly perceive the failure.
Key Novelty
Execution Video Reward Modeling (ExeVRM) with Spatiotemporal Pruning
- Treats agent evaluation as a video understanding task: inputs are user instructions and execution videos (sequences of keyframes), independent of internal agent traces (logs/code)
- Uses Spatiotemporal Token Pruning (STP & TTP) to discard redundant background pixels and static temporal frames, preserving only decisive UI changes (e.g., cursor moves, text edits)
- Generates hard negative training examples via 'Adversarial Instruction Translation', where a model creates plausible but mismatched instructions for successful trajectories
Architecture
The Spatiotemporal Token Pruning workflow: Spatial Pruning (STP) per frame followed by Temporal Pruning (TTP) across frames
Evaluation Highlights
- ExeVRM 8B achieves 84.7% accuracy on video-execution assessment, surpassing Seed-2.0 Pro (+4.4%) and GPT-5.2 (+9.7%)
- Achieves 87.7% recall, significantly outperforming Seed-2.0 Pro (74.7%) and GPT-5.2 (66.5%)
- Maintains tractable training costs on long-horizon videos by using 720p inputs with token pruning, which improves completion judgment compared to downsampled 360p baselines
Breakthrough Assessment
9/10
Proposes a scalable, model-agnostic evaluation standard for the rapidly growing field of computer-use agents, effectively addressing the data scarcity and compute bottlenecks of video-based reward modeling.