📝 Paper Summary
Brazilian Portuguese LLMs
Legal domain adaptation
Agentic capabilities
Sabiá-4 enhances Brazilian Portuguese performance capabilities through a four-stage pipeline involving legal-domain continued pre-training, context expansion to 128k, and agent-focused alignment.
Core Problem
Generalist language models often lack the specific cultural, linguistic, and legislative knowledge required for high-stakes Brazilian legal tasks and complex agentic workflows in Portuguese.
Why it matters:
- Generic models struggle with the nuances of Brazilian federal legislation (over 50,000 acts), leading to inaccuracies in drafting legal documents or judicial decisions
- Previous generations of Portuguese models showed degradation in multi-turn dialogues and inability to handle zero-shot instruction following effectively
- High-performance models are often cost-prohibitive; there is a need for specialized models that offer a better cost-performance trade-off for production retrieval-augmented generation (RAG) workflows
Concrete Example:
In legal drafting, a generic model might fail to correctly identify the specific law corresponding to a legislative excerpt among 50,000+ norms, or struggle to maintain format constraints across a 3-turn instruction sequence (Multi-IF benchmark).
Key Novelty
Four-Stage Domain Specialization Pipeline
- Uses 'Continued Pre-training' on a massive Portuguese and Brazilian legal corpus to specialize a generalist base model before fine-tuning
- Implements a dedicated 'Long-context extension' phase to reach 128k tokens using naturally long documents, preventing the 'lost-in-the-middle' phenomenon common in naive extensions
- Combines supervised fine-tuning (SFT) on synthetic agentic data with preference alignment to strictly enforce formatting for tool use and legal writing
Architecture
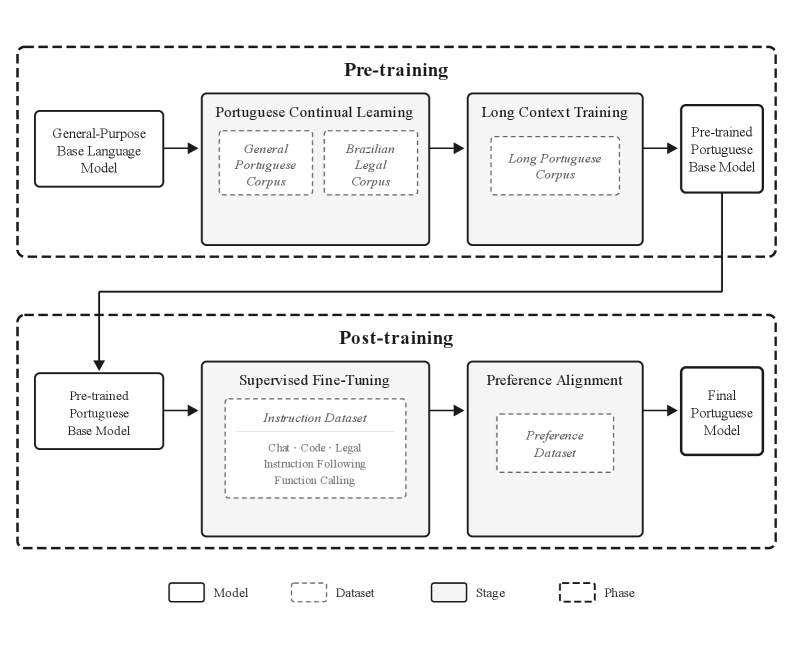
The four-stage training pipeline developed for Sabiá-4.
Evaluation Highlights
- Achieves >98% accuracy on the Needle in a Haystack (NIAH) benchmark, saturating the metric and prompting the use of harder tests like MRCR
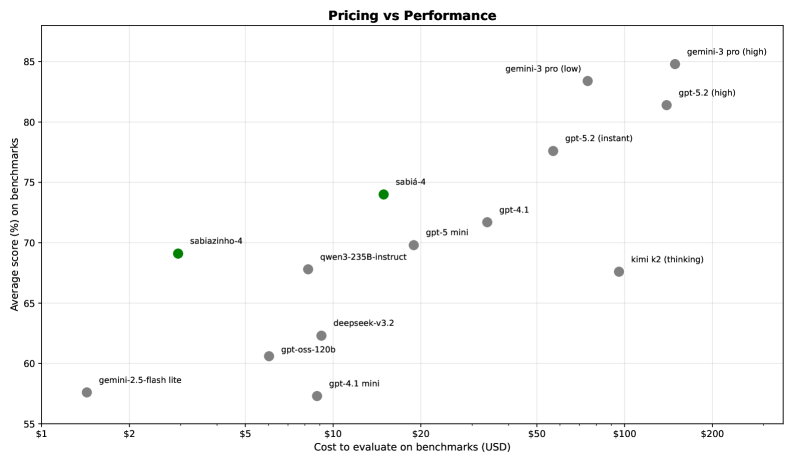
- Demonstrates favorable cost-performance trade-off, positioning in the upper-left region of pricing-accuracy charts compared to state-of-the-art models
- Shows qualitative improvements in drafting civil and criminal judgments over previous Sabiá-3 generations
Breakthrough Assessment
7/10
Strong engineering report demonstrating how domain-specific continued pre-training effectively specializes LLMs. While architectural novelty is low, the pipeline's effectiveness for regional/legal adaptation is significant.