📊 Experiments & Results
Evaluation Setup
Fine-tuning aligned LLMs on downstream tasks and evaluating both task performance and safety retention
Benchmarks:
- GSM8K (Mathematical reasoning)
- MATH (Mathematical reasoning)
- WildJailbreak (Safety evaluation (adversarial))
- Beavertails (Safety evaluation)
- HellaSwag (Common sense reasoning)
Metrics:
- Harmful Score (HS)
- Downstream Task Accuracy (Acc)
- Statistical methodology: Experiments repeated three times; averages reported.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Safety preservation results on Llama-3-8B-Instruct showing GR-SAP effectiveness compared to unmixed and open-source data mixing. | ||||
| Average Safety (4 datasets) | Harmful Score (HS) | 6.28 | 0.58 | -5.70 |
| Average Safety (4 datasets) | Harmful Score (HS) | 31.60 | 0.58 | -31.02 |
| Average Safety (4 datasets) | Harmful Score (HS) | 38.75 | 6.89 | -31.86 |
| Average Safety (4 datasets) | Harmful Score (HS) | 6.86 | 1.15 | -5.71 |
Experiment Figures
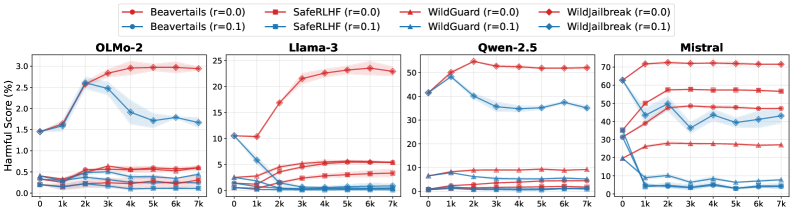
Training dynamics of Harmful Score (HS) over training steps for Llama3, Qwen, Mistral, and OLMo2 on GSM8K and MATH tasks
Main Takeaways
- Fine-tuning on benign tasks (like Math) consistently degrades safety alignment in unmixed settings across all tested models (Llama3, Mistral, Qwen, OLMo2)
- Mixing in open-source safety datasets (Beavertails, AEGIS) often fails to preserve safety and can sometimes drastically increase harmfulness due to distribution mismatch
- GR-SAP synthetic data achieves safety preservation comparable to using the original alignment data (validated on OLMo2 where original data is available)
- Including 'difficult' cases (revised unsafe responses) is more effective than only using 'easy' safe responses