📝 Paper Summary
Knowledge Distillation
Reasoning Models
HEAL improves reasoning distillation by actively repairing the teacher's failed trajectories on hard problems using entropy-guided hindsight hints and filtering shortcuts via perplexity ratios.
Core Problem
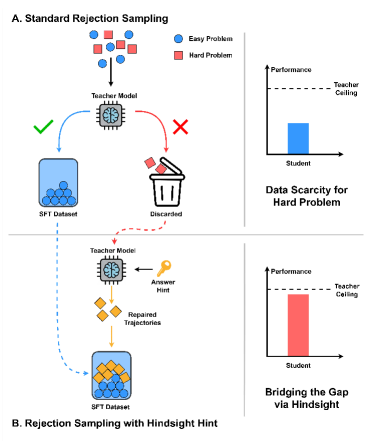
Standard distillation relies on rejection sampling, where the teacher model acts as a static filter and fails to generate valid trajectories for complex 'corner-case' problems, discarding them as unsolvable.
Why it matters:
- Creates an artificial 'Teacher Ceiling' where the student is trained primarily on easy-to-medium samples
- Approximately 13% of hard problems (e.g., AIME 2025) remain unsolved by the teacher even with 64 samples, wasting valuable training data
- Student models are deprived of learning from the most challenging segment of the problem distribution
Concrete Example:
On a hard math problem, a teacher model might repeatedly fail to generate the correct answer independently. Standard rejection sampling discards this problem. HEAL instead detects where the teacher gets stuck (entropy spike) and injects the ground truth answer as a hint to 'repair' the trajectory, turning a failure into a training example.
Key Novelty
Hindsight Entropy-Assisted Learning (HEAL)
- Mimics the Zone of Proximal Development (ZPD) by detecting 'reasoning dead-ends' via entropy spikes and injecting hints only when necessary to bridge the gap between unaided and guided capability
- Filters 'cheating' shortcuts where the model forces the answer without logic by comparing step-wise perplexity against answer uncertainty (PURE)
- Organizes training into a three-stage curriculum (PACE): foundational independent paths, global hindsight paths, and finally entropy-repaired complex paths
Architecture
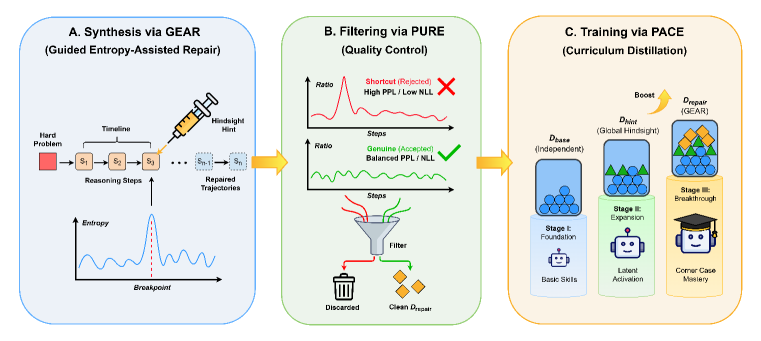
The overall HEAL framework, illustrating the three core modules: GEAR (Synthesis), PURE (Filtering), and PACE (Training).
Evaluation Highlights
- Significantly outperforms standard SFT distillation and other baselines across multiple benchmarks.
- Effectively reduces the 'Teacher Ceiling' by converting 13% of previously unsolvable hard problems into valid training signals via trajectory repair.
- Demonstrates robust improvements on complex reasoning tasks like mathematical problem-solving compared to direct rejection sampling.
Breakthrough Assessment
7/10
Addresses a critical bottleneck in reasoning distillation (the 'Teacher Ceiling') with a theoretically grounded (ZPD) and methodologically sound approach (entropy repair + shortcut filtering). Strong empirical motivation.