📝 Paper Summary
Context-aware adaptation
Non-stationary environment adaptation
The paper enables robots to adapt to changing unobservable environmental conditions by estimating a low-dimensional Trend ID vector via backpropagation on few-shot data, keeping model weights fixed to prevent forgetting.
Core Problem
Robotic systems face concept shift where hidden factors (e.g., moisture) change the input-output relationship without altering visual appearance, causing pre-trained models to fail.
Why it matters:
- Updating model parameters for every environmental change causes catastrophic forgetting of previous conditions
- Frequent retraining is computationally expensive and impractical for real-time robotic operations
- Visual sensors often cannot detect latent physical changes (like density or friction), leading to manipulation failures
Concrete Example:
In a food grasping task, the moisture content of granular food fluctuates with humidity. A robot trained on dry food will misjudge the weight of moist food despite identical visual appearance, leading to failed grasps.
Key Novelty
Latent Trend Embedding with Test-Time Optimization
- Instead of tuning network weights, the system learns a low-dimensional 'Trend ID' vector representing the current environmental state
- At inference time, this Trend ID is optimized via backpropagation using a small number of support samples (5-10), allowing the model to 'slide' to the correct environmental context without forgetting others
- Uses temporal regularization (state transition, velocity, and position consistency losses) to prevent the model from ignoring the image and overfitting to the Trend ID ('ID leak')
Architecture
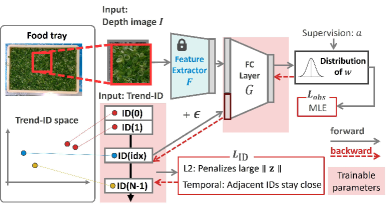
The training and inference schemes. During training, both the MLP (G) and Trend IDs are updated. During inference, only the Trend ID is updated using support samples.
Breakthrough Assessment
7/10
Clever application of test-time latent optimization to robotics, addressing the specific problem of invisible concept shift. While the core idea resembles Generative Latent Optimization, the application to non-stationary regression with temporal constraints is practical and well-motivated.