📊 Experiments & Results
Evaluation Setup
Controlled sweeps over FLOPs ratio r across multiple model scales and sparsity levels to find loss minima
Benchmarks:
- Language Modeling Loss (Autoregressive Next-Token Prediction)
Metrics:
- Training Loss (Cross-Entropy)
- Optimal FLOPs ratio r*
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Empirical validation of the scaling law showing high predictive accuracy for loss and the ability to generalize to unseen sparsity levels. | ||||
| Language Modeling Loss | Loss | See Figure 3 | See Figure 3 | Near-perfect alignment |
| Language Modeling Loss | Loss | See Figure 3 | Predicted Loss | Strong alignment |
Experiment Figures
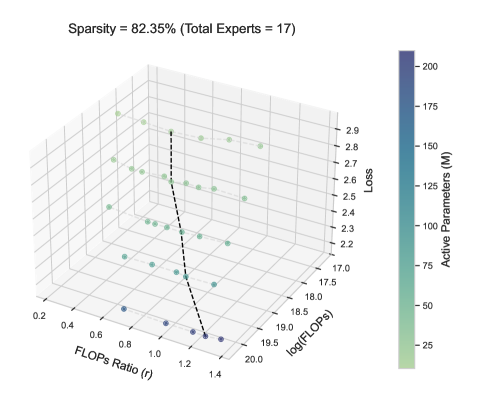
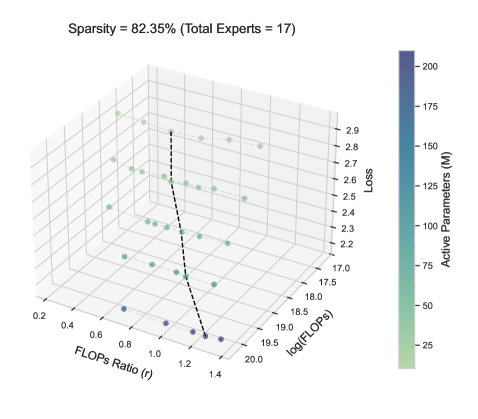
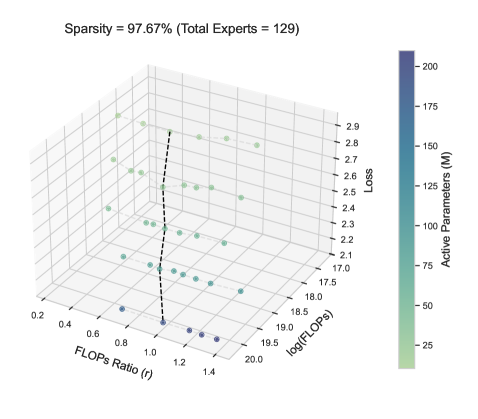
Training loss landscapes vs. FLOPs ratio r and Total Compute C for two sparsity levels.
Scaling behavior of the optimal ratio r* and its coefficients.
Predictive accuracy of the extended scaling law.
Main Takeaways
- The optimal expert-attention ratio r* is not constant; it follows a power law with total compute (C).
- Sparsity (S) significantly alters the scaling coefficients: lower sparsity (more active experts) leads to a steeper increase in r* as compute grows.
- Misallocating compute (deviating from r*) results in systematic performance degradation, quantifiable by the proposed extended scaling law.
- The derived law allows practitioners to analytically determine the optimal architecture (expert capacity) for a given compute budget and sparsity target.