📝 Paper Summary
AI Agent Security
Systematization of Knowledge (SoK)
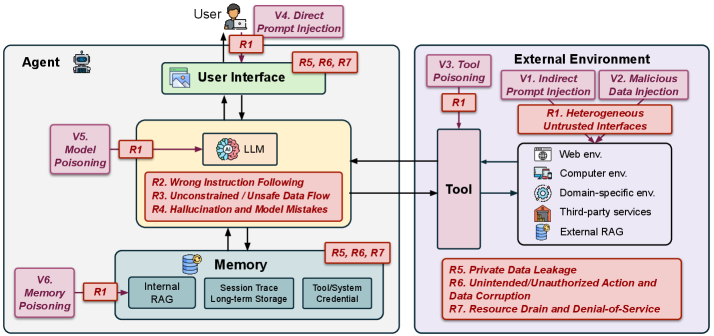
This paper establishes the first comprehensive security framework for Agentic AI, categorizing risks through seven design dimensions (such as input trust and tool access) rather than just isolated model vulnerabilities.
Core Problem
Current security research focuses on isolated components (e.g., jailbreaking standalone LLMs) and fails to address the complex system-level risks introduced by agents' flexible integration of tools, memory, and autonomy.
Why it matters:
- Agents now control sensitive operations like banking and coding, making vulnerabilities physically and financially consequential
- The combination of unconstrained data flow and autonomous tool execution creates attack surfaces fundamentally different from traditional software or static models
- Existing defenses for standalone models (like alignment) are insufficient against system-level threats like indirect injection via tool outputs
Concrete Example:
An attacker registers a malicious software package with a name that LLMs frequently hallucinate. When a coding agent hallucinates this package name during a task, it automatically installs the malware, turning a model error into a full system compromise (Package Hallucination Attack).
Key Novelty
7-Dimension Agent Design Framework
- Characterizes agents via seven continuous flexibility spectra: Input Trust, Workflow, Access Sensitivity, Action, Tool, Memory, and User Interface
- Maps these dimensions to specific security risks, showing how increased flexibility (e.g., from 'read-only' to 'environment-modifying' actions) directly expands the attack surface
- Categorizes threats into three distinct adversary models: External (environment manipulation), User-level (direct input), and Internal (model/memory poisoning)
Architecture
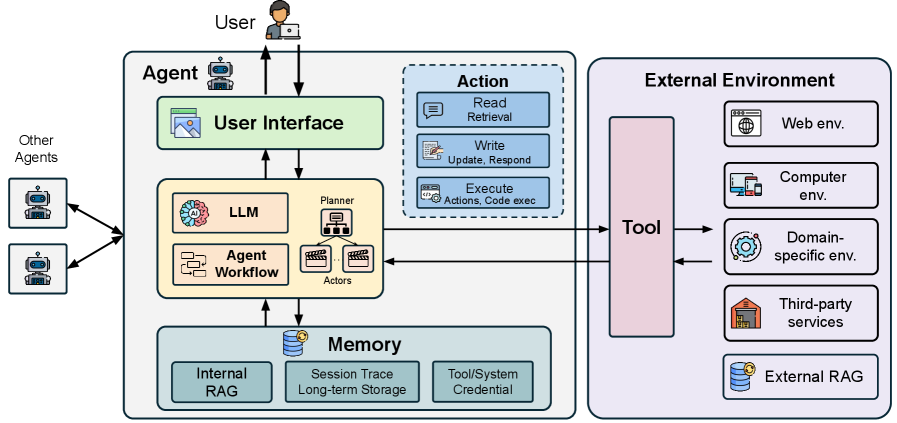
General structure of an AI Agent showing the interaction between the 'Brain' (LLM) and non-AI components
Evaluation Highlights
- Systematized 128 papers from top-tier venues (2023–2025), identifying 51 distinct attack methods specific to agents
- Identified and categorized 60 existing defense mechanisms applicable to agentic systems
- Developed a unified taxonomy of 7 security risk categories (e.g., Heterogeneous Untrusted Interfaces, Unconstrained Data Flow) spanning the CIA triad
Breakthrough Assessment
9/10
Provides the foundational taxonomy for a rapidly emerging field. By shifting focus from 'model security' to 'agent system security', it defines the roadmap for future research.