📝 Paper Summary
Low-bit LLM Training
Quantization-Aware Training (QAT)
Activation Analysis
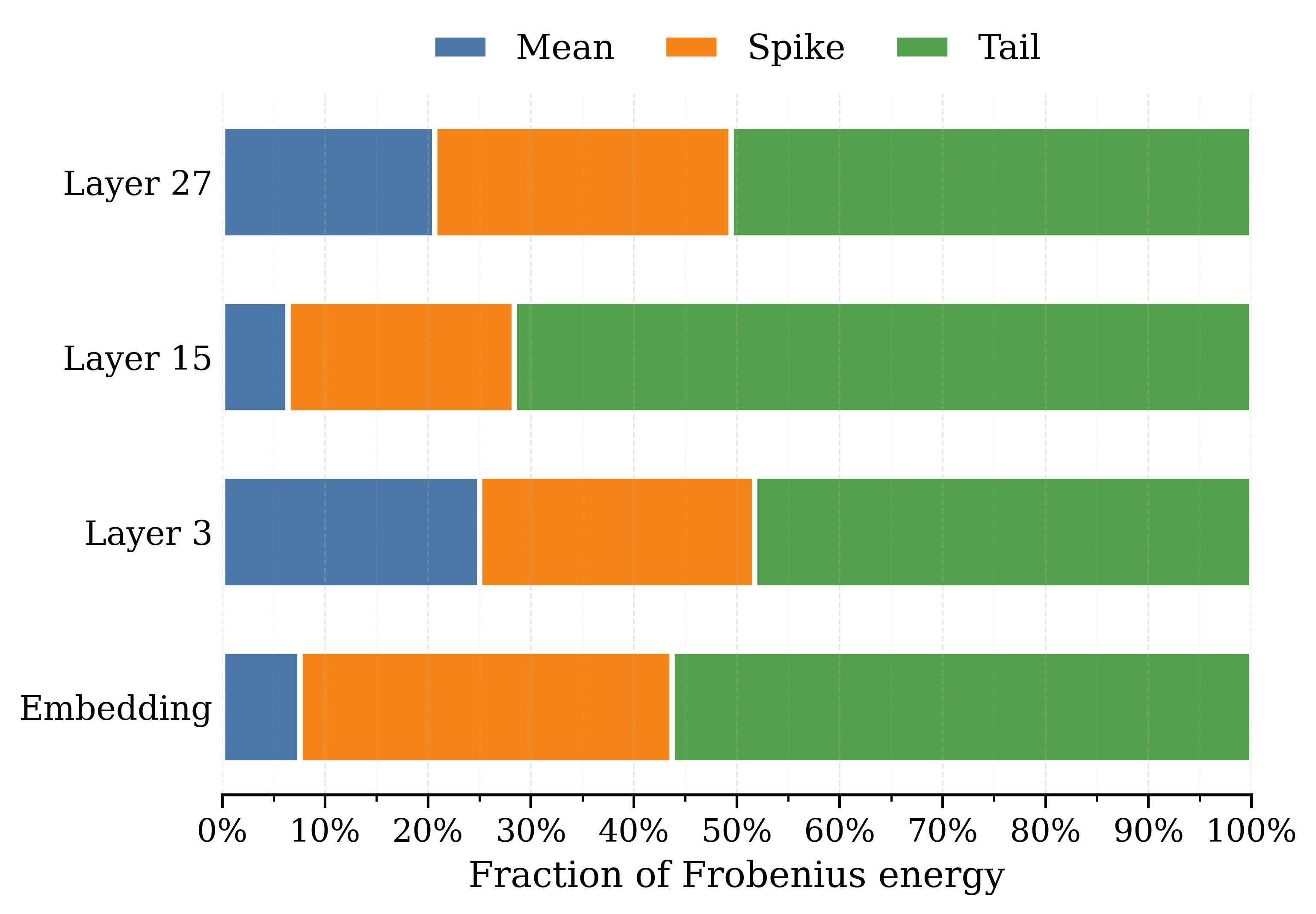
The paper identifies coherent rank-one mean bias as the primary cause of activation outliers in LLMs and proposes removing this mean before FP4 quantization to restore training stability.
Core Problem
Blockwise low-bit quantization fails because extreme activation values stretch the dynamic range, compressing the semantic signal into narrow bins; current mitigation methods (like SVD) are computationally expensive.
Why it matters:
- Extreme activations (outliers) dictate the quantization scale (L-infinity norm), causing severe precision loss for the vast majority of 'normal' semantic data
- Prior methods like SVD or orthogonalization are too slow and memory-intensive for efficient hardware implementation
- Without stable low-bit training, deploying massive LLMs on resource-constrained hardware remains inefficient
Concrete Example:
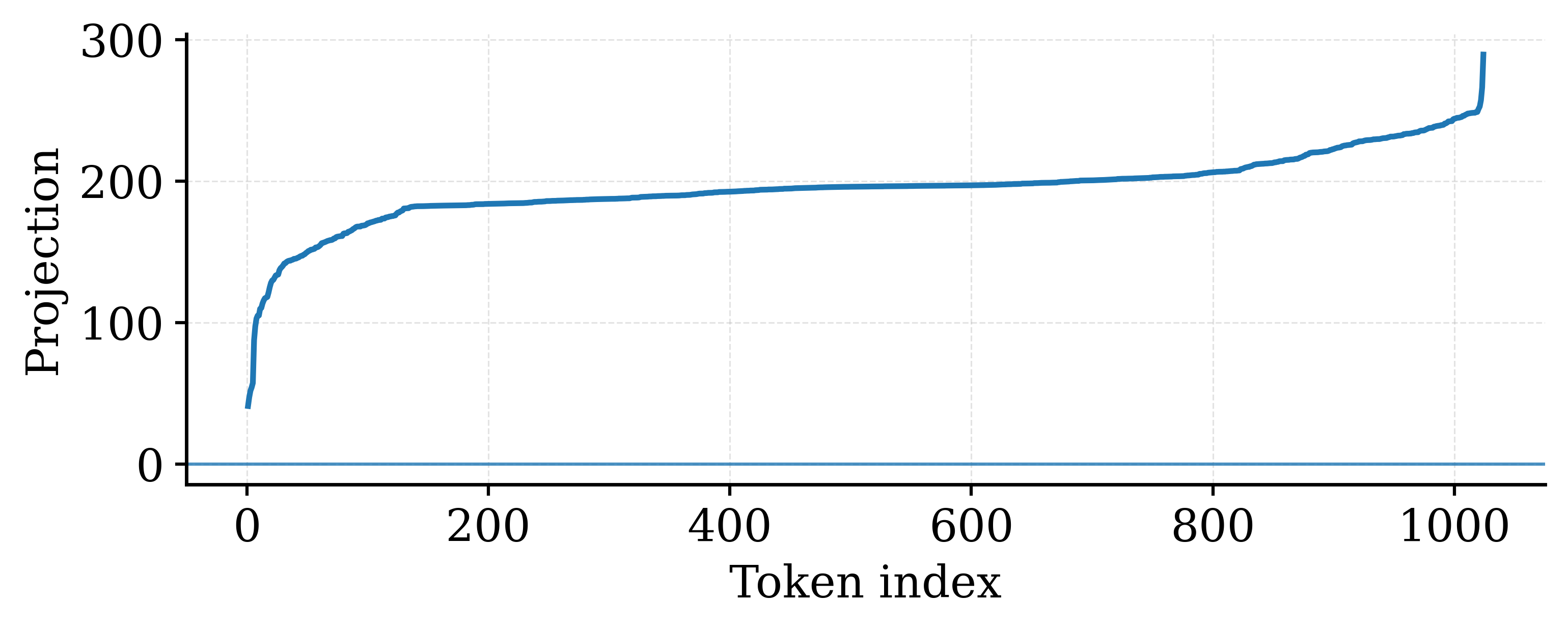
In late-stage Qwen3-0.6B, tokens in Layer 27 exhibit a coherent directional shift where projection signs are nearly uniform. This 'mean bias' scales with the hidden dimension (sqrt(H)), creating massive values that force the quantization grid to widen, drowning out smaller, semantically important variations.
Key Novelty
Averis (Averaging-Induced Residual Splitting)
- Discovers that activation outliers are not random but driven by a coherent, rank-one mean shift accumulated across layers
- Proposes explicitly calculating and subtracting this column-wise mean before quantization, then quantizing the mean and residual separately
- Replaces complex spectral operations (SVD) with simple reduction (averaging) and elementwise subtraction, making it hardware-efficient
Architecture
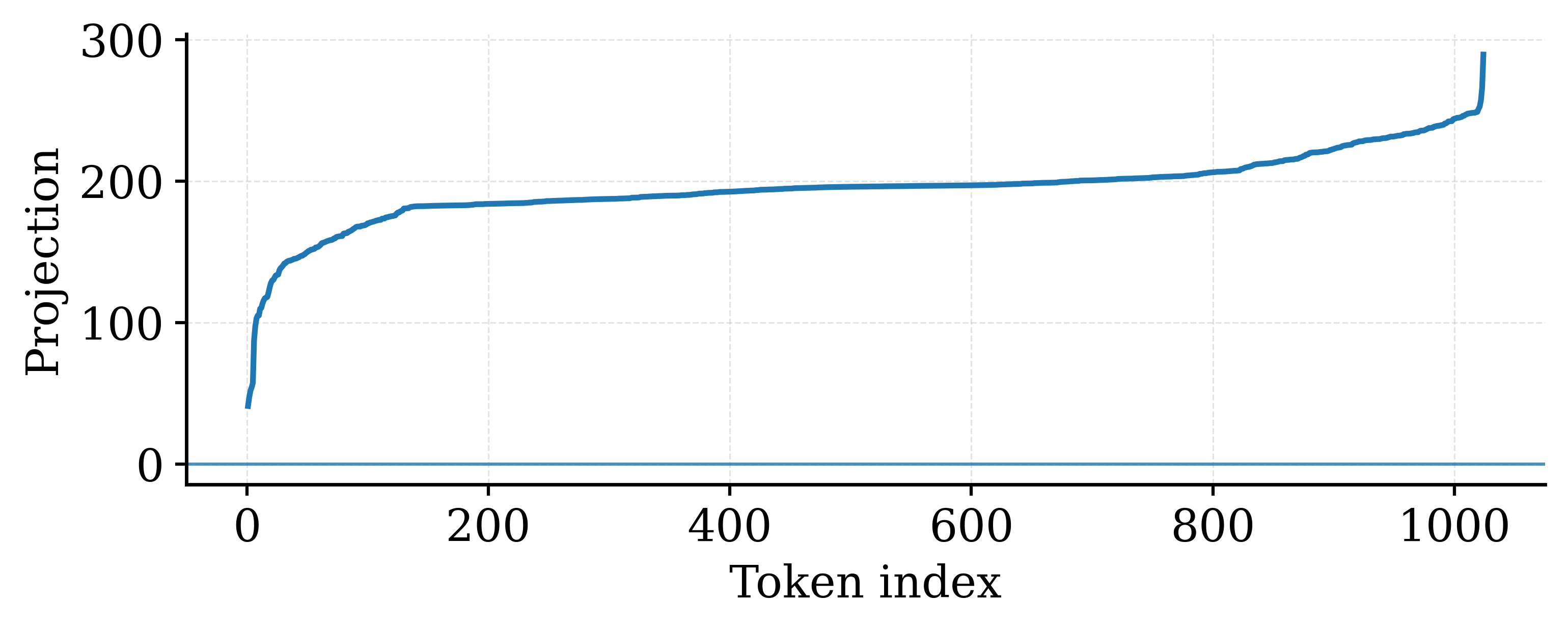
Visualization of token-wise projection signs in late-stage Qwen3-0.6B (Layer 27 FFN input).
Evaluation Highlights
- Mean removal narrows the training loss gap to BF16 significantly compared to standard quantization baselines
- Restores downstream task performance on 1B-scale models trained with FP4 (W4A4G4)
- Demonstrates that the mean direction aligns (cosine similarity ~0.99) with the leading anisotropic spike identified by computationally expensive methods like Metis
Breakthrough Assessment
7/10
Provides a strong theoretical insight linking outliers to mean bias and offers a very simple, hardware-friendly fix (subtraction) that replaces expensive SVD methods.