📝 Paper Summary
Physics-Informed Neural Networks (PINNs)
Multi-task Learning (MTL)
Scientific Machine Learning (SciML)
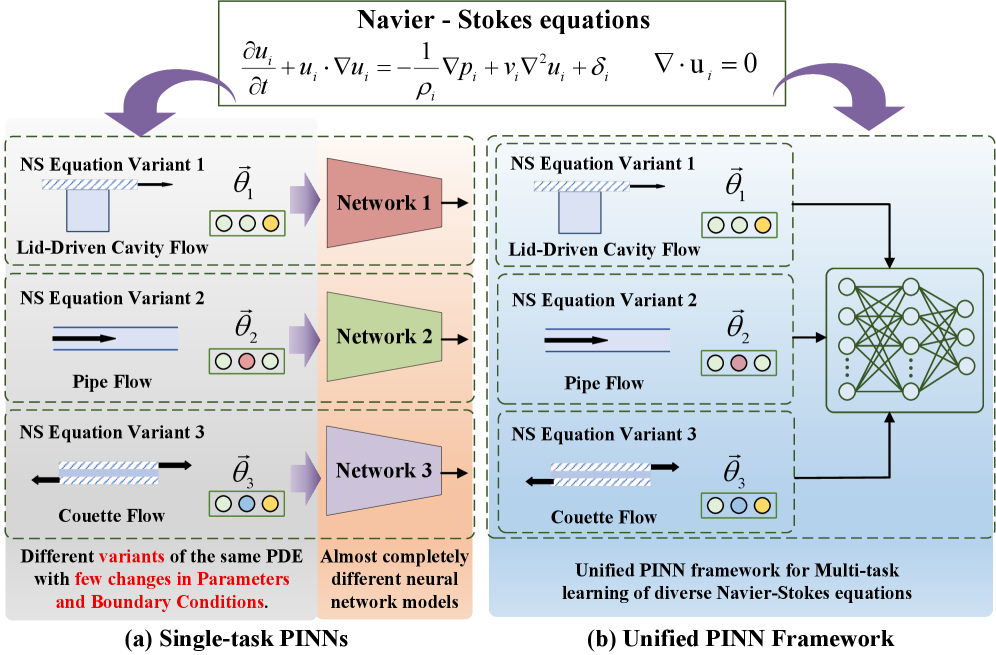
UniPINN unifies the learning of diverse Navier-Stokes flows into a single network using a shared-specialized architecture, cross-flow attention for knowledge transfer, and dynamic weight allocation to balance conflicting gradients.
Core Problem
Standard PINNs are designed for single-flow settings and struggle when extended to multi-flow scenarios due to negative transfer, rigid weight sharing, and severe gradient pathologies caused by disparate loss magnitudes.
Why it matters:
- Real-world fluid problems involve diverse regimes (varying viscosity, geometry) that currently require training independent networks for each case, incurring high computational costs.
- Existing methods fail to exploit universal physical laws shared across flows (e.g., Navier-Stokes equations), missing opportunities for data-efficient knowledge transfer.
- Naive multi-task learning leads to gradient pathology, where dominant loss terms suppress others, causing the model to violate fundamental physical constraints in certain flow regimes.
Concrete Example:
When training on multiple flows simultaneously, variations in parameters like viscosity alter the dominance of convective vs. diffusive terms. A standard PINN might optimize for a high-magnitude loss flow (e.g., high velocity) while failing to resolve boundary layers in a lower-magnitude flow, degrading physical accuracy.
Key Novelty
Shared-Specialized Architecture with Dynamic Gradient Balancing
- Decomposes the network into a shared backbone for universal laws (Navier-Stokes) and specialized heads for flow-specific boundary conditions, preventing negative transfer.
- Introduces a cross-flow attention mechanism that allows the model to selectively 'borrow' relevant features (like vortex patterns) from other flow regimes while ignoring irrelevant ones.
- Uses a dynamic weight allocation strategy that monitors training residuals in real-time to adjust loss weights, ensuring no single flow regime dominates the optimization.
Architecture
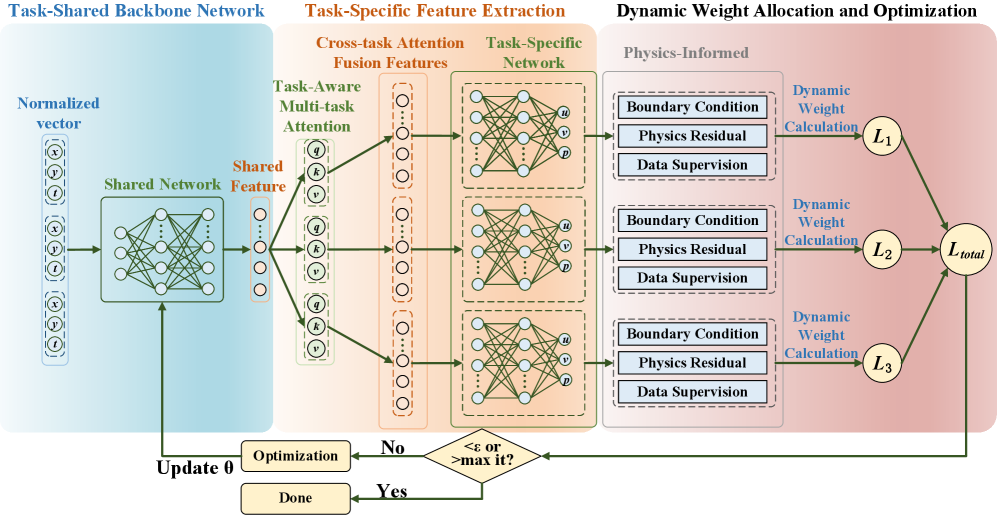
The overall UniPINN framework showing the shared backbone, task-specific embedding injection, cross-flow attention mechanism, and specialized output heads.
Evaluation Highlights
- Achieves superior prediction accuracy compared to independent PINNs and standard multi-task baselines across three canonical flow problems.
- Successfully unifies multi-flow learning without the performance degradation typically caused by negative transfer in naive multi-task settings.
- Demonstrates robust convergence stability by effectively balancing loss magnitudes that span several orders of magnitude across heterogeneous tasks.
Breakthrough Assessment
7/10
Strong methodological contribution effectively addressing the specific bottlenecks of multi-task PINNs (gradient pathology, negative transfer). While applied to canonical flows, the architectural decoupling is a significant step for scalable SciML.