📝 Paper Summary
Web agents
Synthetic environment generation
Agentic reinforcement learning
VeriEnv uses coding agents to clone real websites into executable sandboxes, enabling web agents to learn from self-generated tasks with deterministic, database-backed verification instead of unreliable LLM judges.
Core Problem
Training web agents on real websites is unsafe, hard to reset, and lacks reliable rewards, often forcing reliance on error-prone LLM-as-a-judge evaluations.
Why it matters:
- Real-world exploration is dangerous (spamming, payments) or blocked (CAPTCHAs), limiting the scale of agent training data
- LLM-based evaluation is heuristic and unreliable, leading to unstable learning signals compared to deterministic code-based verification
- Existing benchmarks are static and finite; agents need a scalable way to self-evolve on diverse, continuously expanding tasks
Concrete Example:
A task asking to 'sort apartments by price' might be judged correct by an LLM if the visual output looks sorted, even if the underlying logic failed. In VeriEnv, a Python script queries the simulated database to mathematically verify the sort order.
Key Novelty
VeriEnv (Verifiable Environments via Website Cloning)
- Treats the environment itself as code: A coding agent (GPT-5.2) clones a target website's frontend, backend, and database from screenshots into a local executable
- Generates tasks paired with executable validation programs (using a custom Python SDK) that inspect the internal database state for deterministic pass/fail rewards
Architecture
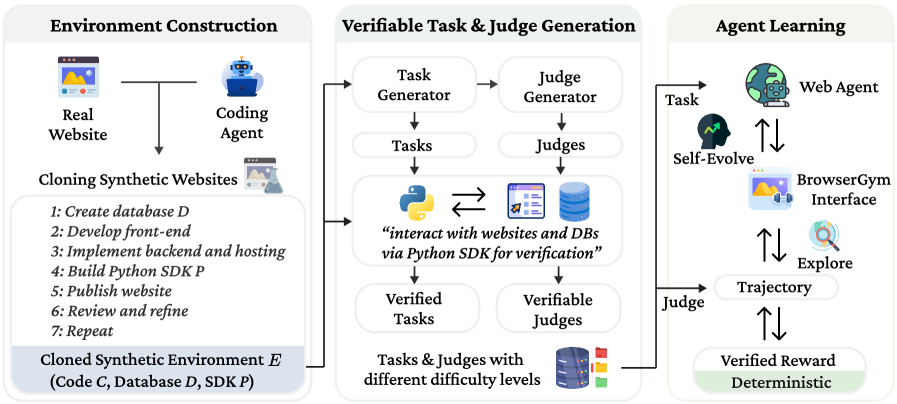
The complete VeriEnv framework workflow: (1) Cloning real websites into synthetic environments, (2) Generating tasks with executable validators, and (3) Training agents via verifiable feedback.
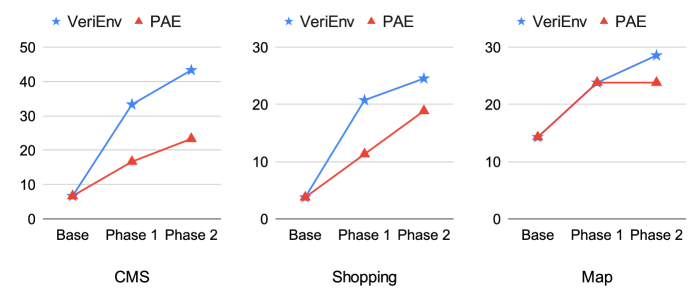
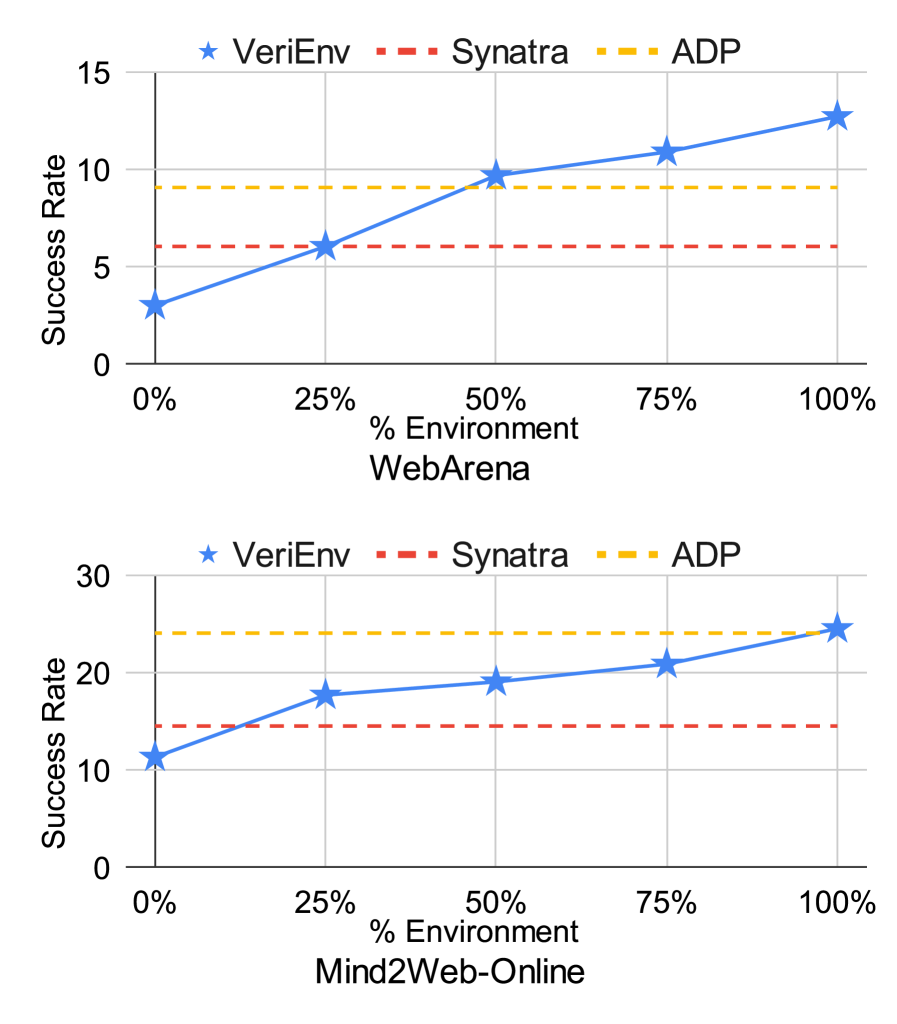
Evaluation Highlights
- +9.09% success rate improvement on WebArena-Lite using LLaMA-3.2-3B-Instruct trained with VeriEnv compared to the base model
- +6.06% success rate improvement on WebArena-Lite using Qwen3-4B trained with VeriEnv compared to the base model
- Functionality ratings of 90.3% and visual quality of 4.7/5 for the synthetically recreated websites based on human evaluation
Breakthrough Assessment
8/10
Significant step forward in agent safety and scalability. Moving from 'simulators' to 'automatically cloned real-world replicas' with verifiable internals solves a major bottleneck in web agent RL.