📝 Paper Summary
Deep Learning Architectures
Graph Neural Networks
Efficient Transformers
SCORE replaces stacks of independent layers with a single shared neural block applied iteratively using a discretized ODE-based contractive update rule to improve stability and reduce parameters.
Core Problem
Standard layer stacking increases parameter counts linearly and treats depth as independent transformations, often leading to optimization instability, vanishing gradients, or oversmoothing in GNNs.
Why it matters:
- Deep GNNs often suffer from oversmoothing, where representations become indistinguishable as depth increases, limiting their performance on molecular tasks
- Large Language Models (LLMs) have massive parameter counts; reducing layer redundancy via recurrence could significantly lower memory footprints
- Classical residual connections (addition) do not explicitly control update magnitude, sometimes failing to stabilize training in specific architectures like MPNNs
Concrete Example:
In a Message Passing Neural Network (MPNN) predicting molecular solubility, simply stacking convolution layers can lead to divergence or performance degradation. SCORE reuses a single convolution block for 4 iterations with a step size delta_t=0.25, forcing a stable, gradual refinement of the molecule's representation.
Key Novelty
SCORE (Skip-Connection ODE Recurrent Embedding)
- Reinterprets depth as a dynamic evolution process where a single shared neural block (e.g., a Transformer layer or Graph Convolution) is applied repeatedly over discrete time steps
- Replaces standard additive skip connections with a 'contractive' weighted update rule (convex combination of old and new state) that mimics an explicit Euler integration step, stabilizing the recurrent dynamics
Architecture
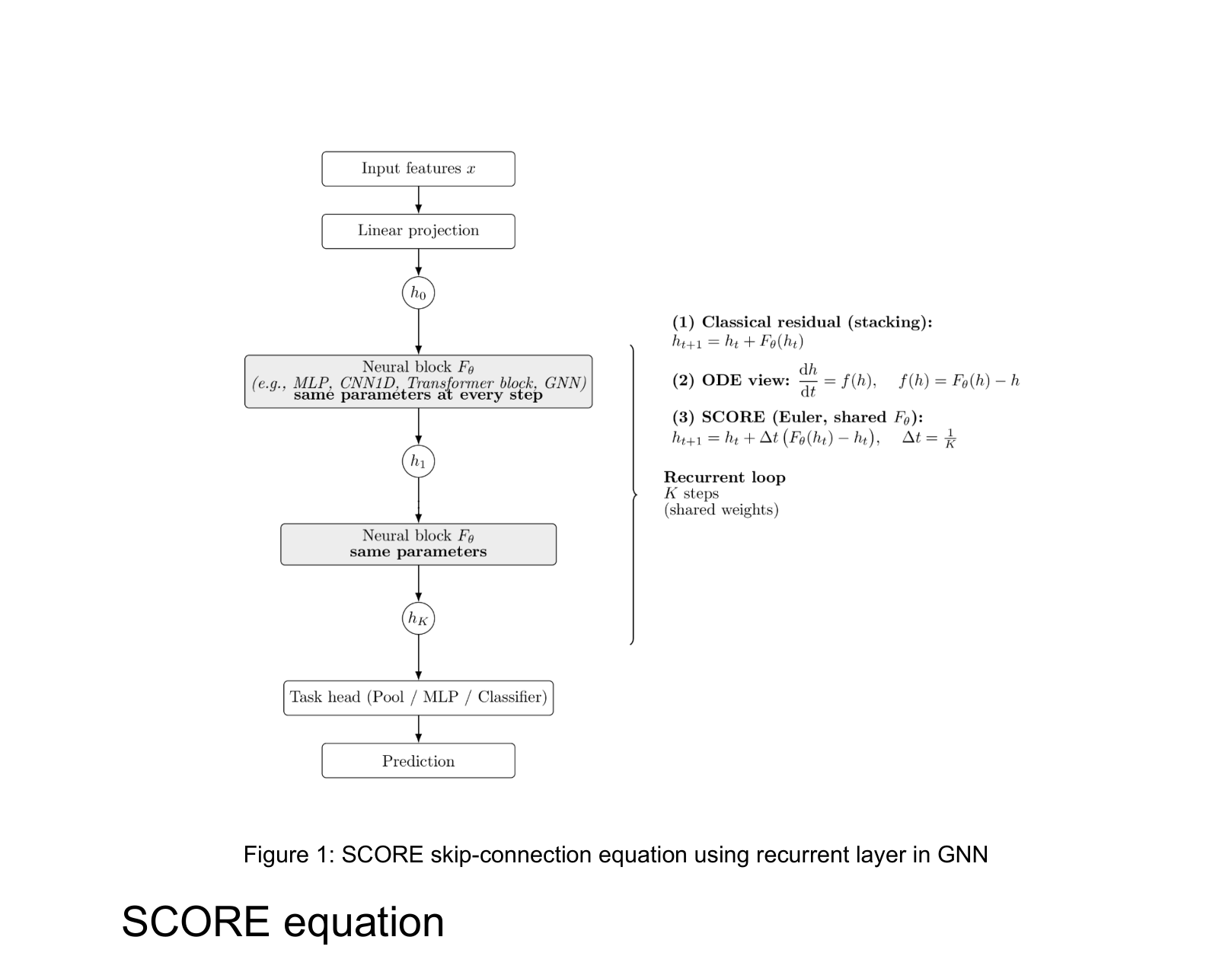
The mathematical formulation of the SCORE update rule and its conceptual difference from layer stacking.
Evaluation Highlights
- Outperforms standard stacking on ESOL molecular solubility: SCORE-DMPNN achieves 0.542 RMSE vs. 0.563 for the strong CatBoost baseline
- Reduces Transformer parameter count by ~18% (28M vs 34M) while improving validation loss (5.41 vs 5.67) on Shakespeare compared to a standard stacked nanoGPT
- Demonstrates broad compatibility: 10 of the top 13 performing GNN configurations on ESOL utilize SCORE or its Euler-based residual formulation
Breakthrough Assessment
7/10
Proposes a simple, effective architectural simplification (recurrent shared blocks) that works across diverse modalities (GNNs, MLPs, Transformers). While the math is a known ODE discretization, the empirical validation across disparate architectures is strong.